

Imagine you are working on a large-scale e-commerce application which uses Kafka for messaging. All seems to be going well until one fine day you look at your metrics dashboard and you start noticing an uptick in the number of deliveries compared to the number of orders placed. This leaves your team scrambling for an answer. After hours of debugging and a lot of coffee, the root cause turns out to not be a coding error, but duplicate messages flooding your topics. In this blog, we will do a deep dive into the scenarios that can lead to duplicates and the various approaches that can be used to avoid them.
Producer side duplicate messages
Let us consider an order service that publishes messages to an order topic.
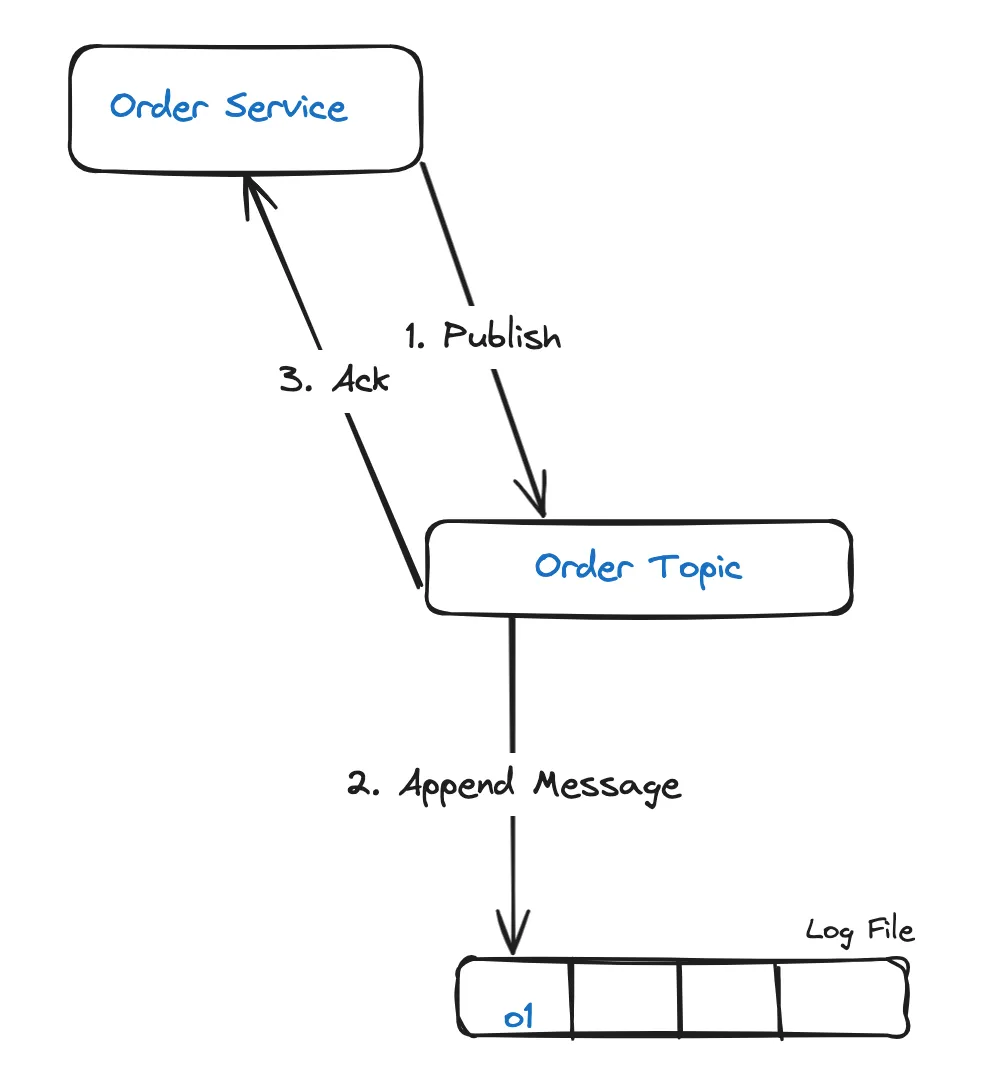
In step 3, it is possible for the acknowledgement from Kafka to be lost due to transient network issues, such as temporary loss of network connectivity. This will lead the order service to retry the same message until a successful acknowledgement is received, resulting in a duplicate.
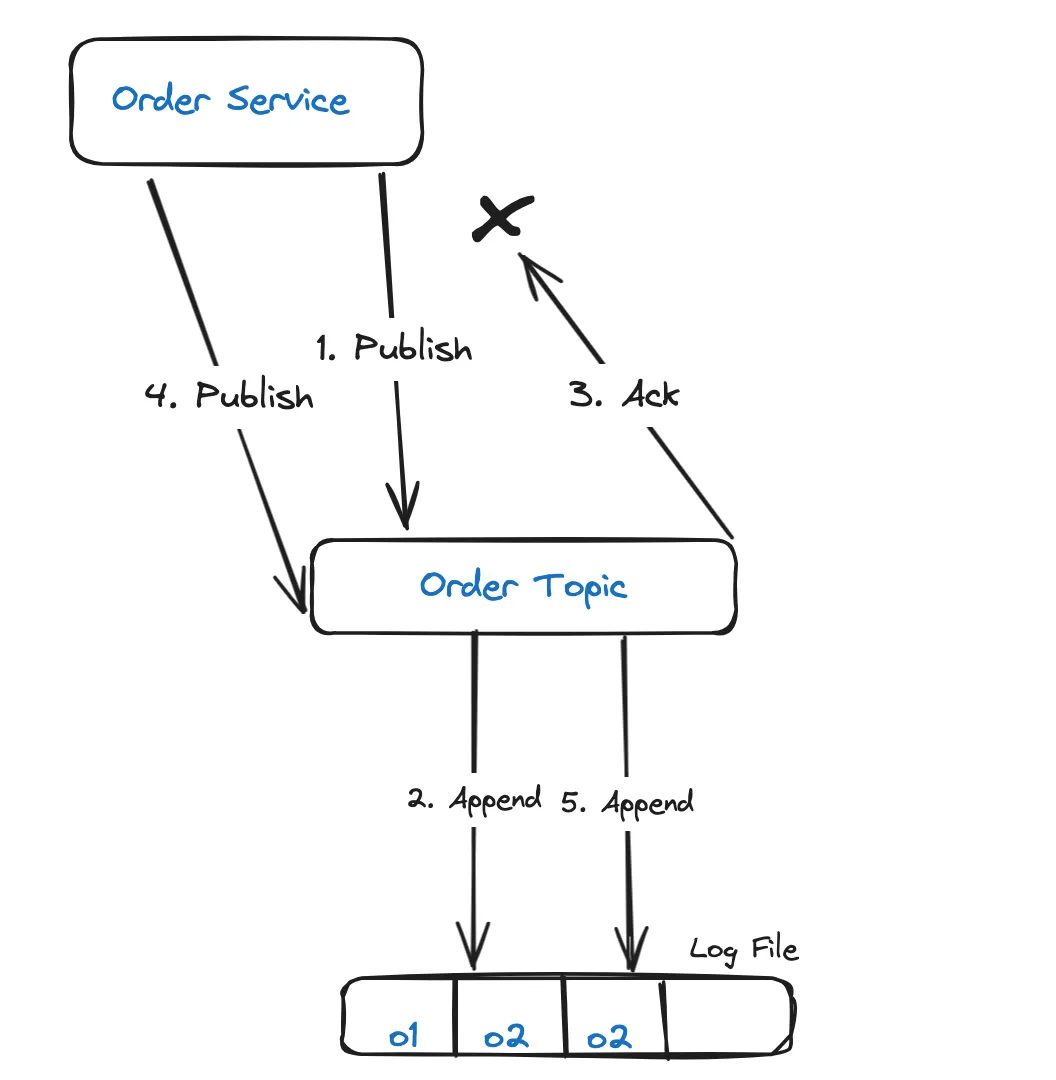
Resolution: Idempotent Producer
Idempotent producer can help resolve the issue. To achieve this, the order service should be assigned a unique producer ID (PID) and each message published should be given a sequence number. The combination of PID and the sequence number is tracked by Kafka as a unique ID for a message. So, when a retry happens for an existing message, Kafka gives an acknowledgement back without appending the message to the log.
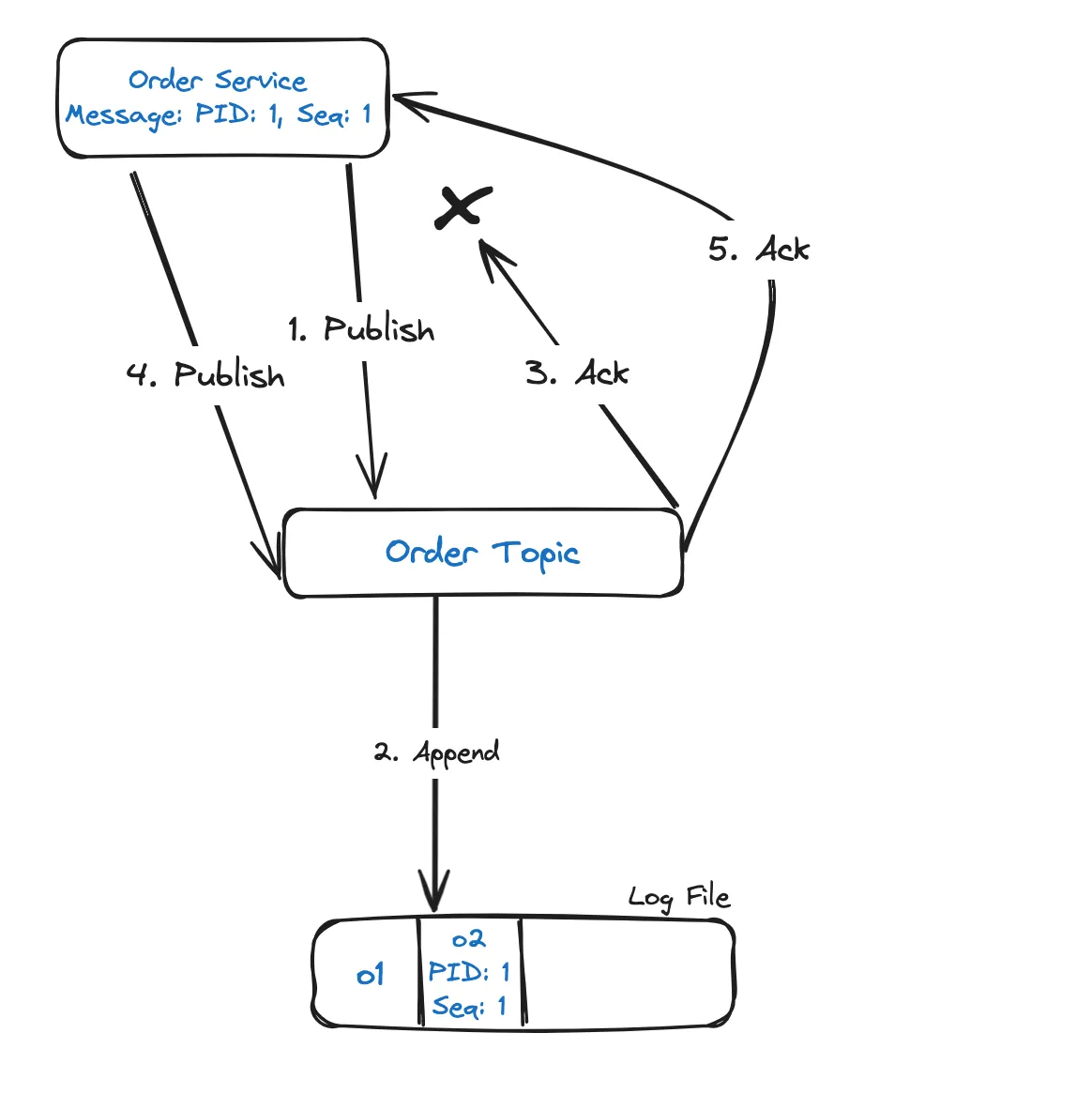
Idempotency can be enabled in Kafka producer by setting
enable.idempotence configuration property to true , retries to a value greater than 0 and acks to all.
enable.idempotence — When set to true , the producer automatically does retries on retryable errors.
These can be errors that are transient in nature, such as leader not available or not enough replicas.
acks — When set to all , Kafka makes sure that the leader waits for minimum number of in-sync replica partitions to have acknowledged the message before sending an acknowledgement to the producer.
Consumer side duplicate messages
Now, let us consider a fulfillment service which:
- Reads messages from the Order Topic.
- Performs a POST call to the Audit Service.
- Creates a new record in the Fulfillment Table.
- Publishes a message to the Fulfillment Topic.
- Updates the offset in Kafka.
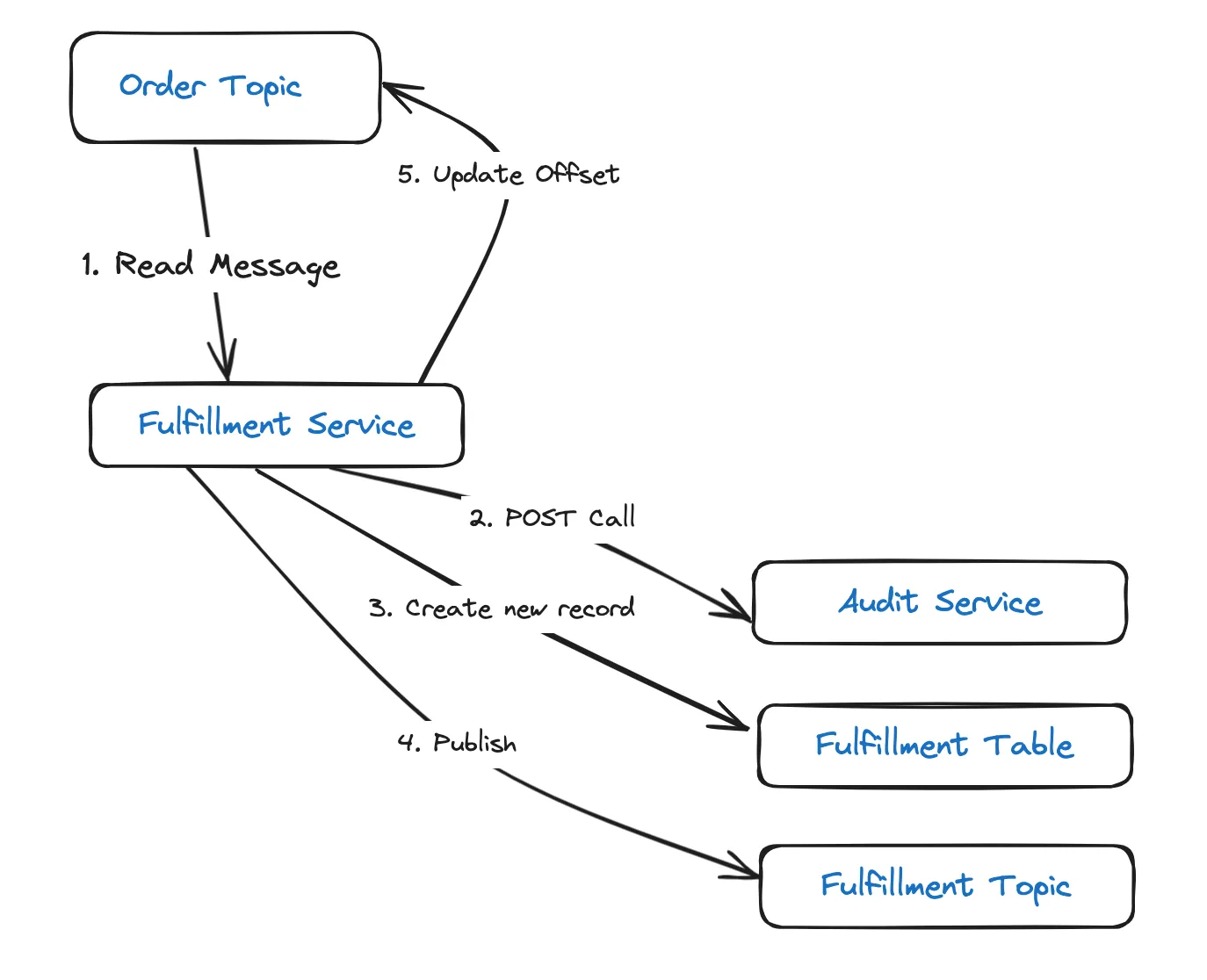
If the instance running the service, does not process steps 2–5 within the set timeout, Kafka will assume that the service is dead. This will cause the service instance to be removed from the consumer group and the partition to be rebalanced. This means, the same message will then be assigned to, and processed by, another consumer in the group.
Resolution: Idempotent Consumer
Tracking all successfully consumed messages can help to avoid this scenario. This can be achieved by assigning a unique ID to every message created at the producer side (order service), and tracking them on the consumer side (fulfillment service) by storing each ID in a database table (Message ID Tracking Table). When a message with a duplicate ID is received(identified by searching the Message ID Tracking Table), the offset is immediately updated and further processing skipped.
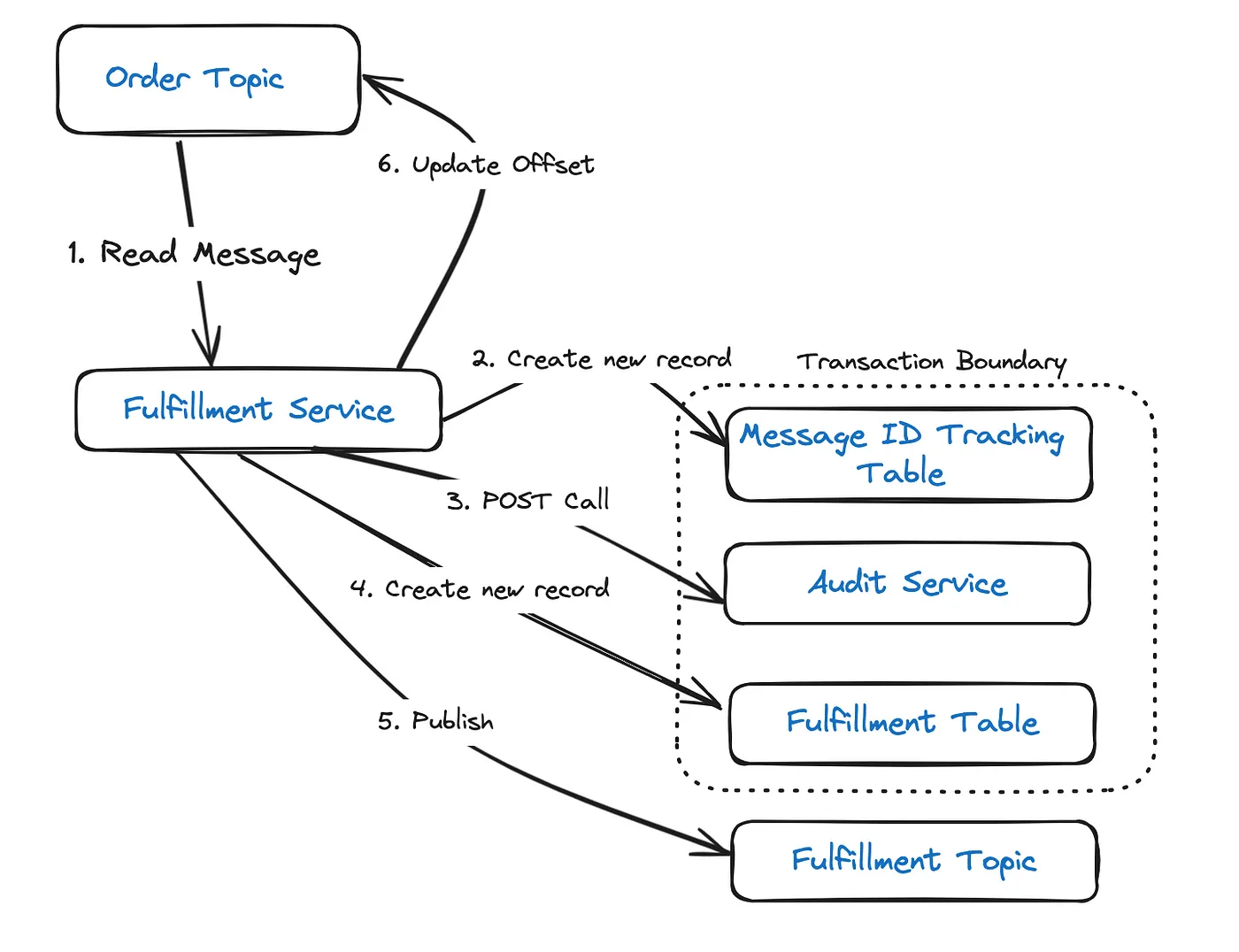
Also, inserting the record into the Tracking and Fulfillment Tables should done as a DB transaction. This ensures that both actions are rollbacked in the event of any failure.
There is a possibility for transaction to fail, after publishing message to the fulfillment topic. This will lead to a retry, which will then result in a duplicate message in the fulfillment topic. This approach does not address this scenario.
Resolution: Idempotent Consumer + Transactional Outbox
It is not possible to have a distributed transaction that would span the database as well as Kafka, as the latter does not support XA transactions. So an approach to resolve the issue, will be to have an outbox table for capturing events to be published. Writes to this table should be included in the same DB transaction which writes to the Tracking and Fulfillment tables.
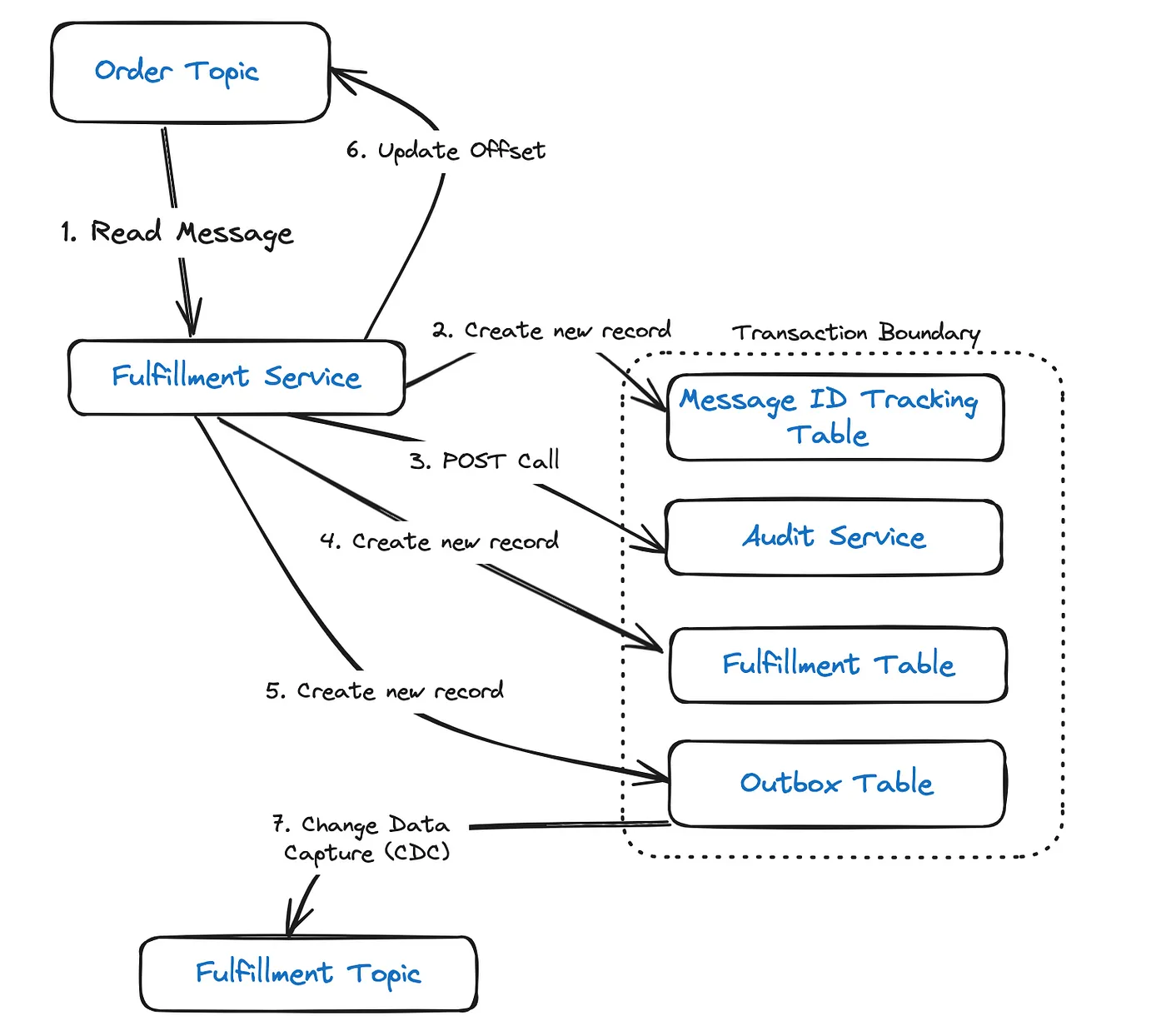
This ensures database writes, and message publishing to Kafka, are an atomic action. By using a Change Data Capture (CDC) tool, such as Kafka Connect or Debezium, the event can then be published to the fulfillment topic.
Even with this approach, there is a still a possibility for duplicate POST calls, since retires can be triggered when there is a transaction failure followed by a rollback after the making the call. This is irrespective of the order of execution of the call. The only resolution for which, will be to make sure that the POST call is idempotent on the receiver side.
Conclusion
These approaches introduce a lot of moving parts which increase complexity and maintainability. So, it will be wise to take an incremental approach and implement them only when there are substantial metrics to support their incorporation.


