In the first part, we explored how raw royalty files are processed and matched with users from the database who are due for payment. In this part, we focus on the next stage: batching the processed records and displaying aggregated results to users with advanced filtering capabilities. Scale continues to be a major challenge, with the customer already managing over 20 billion records in their database and growing. We’ll dive into the specific challenges we faced, one at a time.
Challenges with Bulk CSV Imports and Idempotency
In some cases, the CSV files we received from larger DSPs were massive, going up to 500 million records. Since we needed to group data by users to process payments, streaming and grouping in memory wasn’t practical. To ensure idempotency and avoid partial processing issues, we decided the best approach was to load the data into a database first and then perform the grouping there.
We were using MariaDB as our transactional database, so we chose LOAD DATA INFILE to import the CSVs. It’s the fastest native way to load large volumes directly into a table.
However, two major challenges came up:
- The import itself was extremely slow — roughly 4 hours for 250 million records.
- To maintain idempotency and ensure no duplicate processing, we added unique constraints on the table. But if the worker importing the data crashed (which could happen for a number of reasons), the process had to be restarted from scratch, taking the full 4 hours again.
In one particular run, we encountered a strange edge case: a crash caused a few records to be partially written with a NULL value in a column that was supposed to be unique. When the import was retried, the uniqueness check failed, and four extra rows were accidentally inserted. While we caught the mismatch manually and no actual dollar loss occurred, theoretically it would have been about an $11 discrepancy.
We weren't able to fully pinpoint why this happened — especially since LOAD DATA INFILE is supposed to respect transactions and we had unique constraints defined. It’s possible the server crashed so abruptly that it left the database in a slightly inconsistent state.
If anyone else has faced similar issues while working with LOAD DATA INFILE at this kind of scale, would love to hear your experiences.
Moving to ClickHouse for Faster Bulk Loads
After struggling with massive CSV imports in MariaDB, we realized we were hitting the limits of what it could handle. Even though we were inserting into a temporary table, the performance just wasn’t where we needed it to be. It was taking close to 4 hours to load 250 million records and any crash meant starting all over again.
At that point, it was clear: MariaDB wasn’t built for this kind of bulk load at scale.
That’s when we decided to try ClickHouse, an OLAP database that’s much better suited for heavy read/write operations on large datasets. The difference was immediate. The same 250 million records that took 4 hours in MariaDB were loaded into ClickHouse in about 10 minutes.
ClickHouse’s Native S3 Integration
ClickHouse also opened up new possibilities for us. It has native S3 integration, which meant we could directly load data from S3 into ClickHouse tables and export data back into CSV format straight from the database without routing it through the application. Since pulling large datasets into the app was slow, being able to generate CSVs directly from ClickHouse saved a lot of time on post-processing as well.
In hindsight, shifting to ClickHouse not only solved our immediate loading problem but also gave us a much better foundation for scaling the system as the data volume kept growing.
Balancing OLAP and OLTP: The Hybrid approach
While moving to ClickHouse massively improved our insert speeds, it quickly became clear that we couldn’t get away from needing a transactional (ACID-compliant) database. We still had to perform critical operations like royalty splits, deducting advances, and handling expenses, all of which required reliable database transactions. However, performing transactional operations inside an analytical database like ClickHouse was not ideal.
Since ClickHouse is exceptionally good at aggregation and S3 integrations, we adjusted our workflow:
Instead of trying to load a massive, 40-column CSV into MariaDB, we first loaded the entire file into ClickHouse. There, we aggregated the data down to person-level, album-level, and song-level summaries, depending on what was needed for further processing.
Once aggregated, we pushed much smaller, minimal datasets back into MariaDB, just the columns that were actually required for transactional operations.
Loading these smaller, tightly-focused files into MariaDB using LOAD DATA INFILE was almost instant, completely removing the painful multi-hour imports we were dealing with earlier.
In the end, this hybrid approach gave us the best of both worlds:
- ClickHouse for fast ingestion, aggregation, and S3 file management.
- MariaDB for ACID-compliant transactional workflows. This setup let us scale processing without compromising on correctness or speed and was exactly what we needed for handling royalties at the scale we were targeting.
Speeding Up User Experience with ClickHouse for Aggregated Views
Once all the transactional processing was done, the next challenge was making the data easily accessible to users and showing them how much they had earned, and allowing them to apply advanced filters and aggregations to slice and dice the data.
Initially, we were using a read-only MariaDB replica, storing pre-summarized data in special tables to support the UI. However, we started hitting bottlenecks once the data crossed about 4 billion records. The main issue was that the same table was being used for both inserts and reads, leading to significant contention and performance degradation.
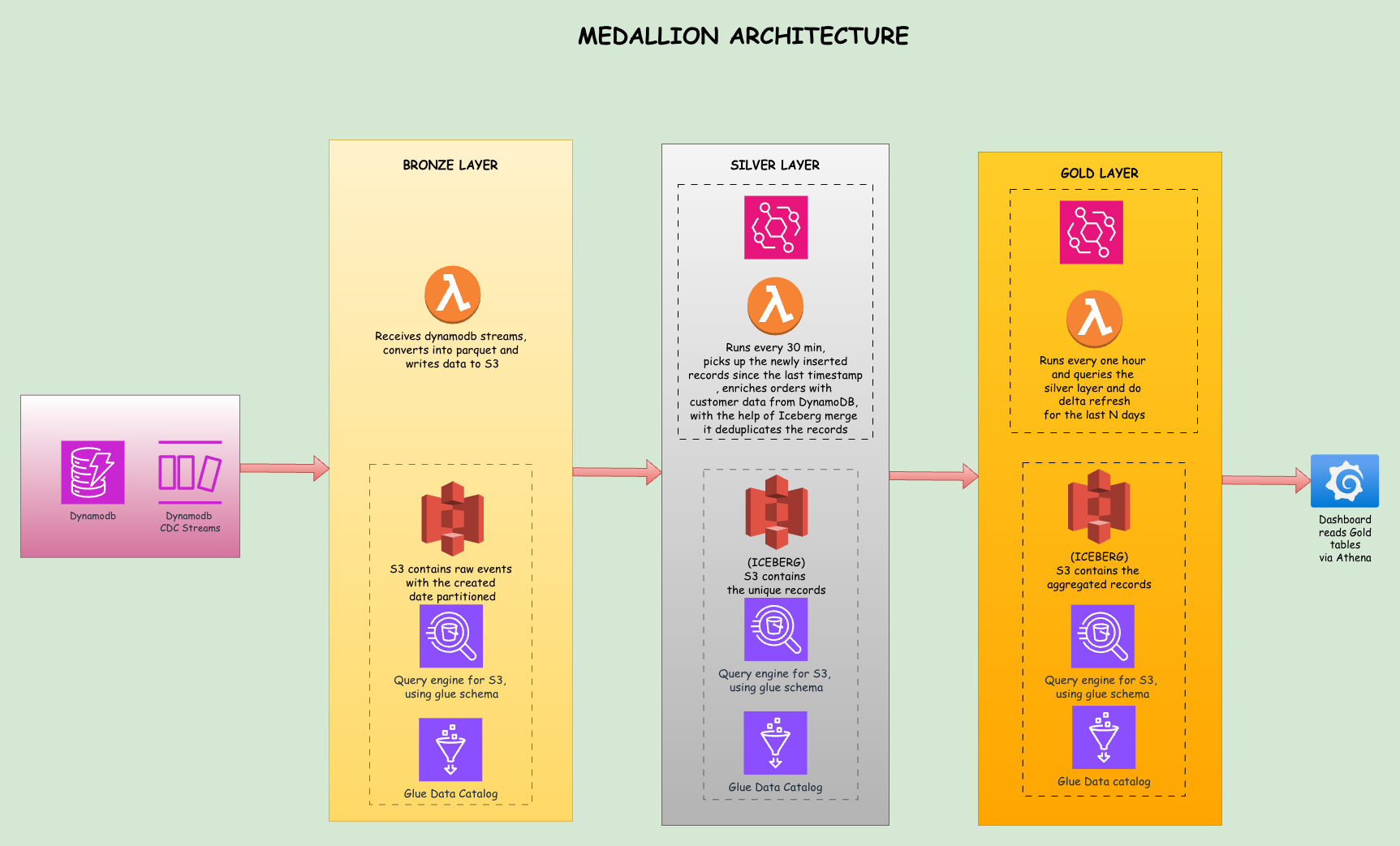
To solve this, we shifted the final storage of processed data to ClickHouse instead of MariaDB in a denormalised way so no join queries were done when UI requests for the data. Since ClickHouse is built for analytical queries, aggregates and filtered reads became lightning fast, especially when we properly used sorting keys.
The result?
The UI responsiveness improved dramatically, users who earlier saw endless loading icons were now able to see their earnings and apply filters almost instantly.
This change not only made the system far more scalable but also elevated the overall user experience, which is critical when dealing with financial data at scale.
— -
This wraps up our two-part series on how we addressed the challenges of processing royalties at massive scale — from handling raw ingestion and ensuring transactional integrity, to optimizing user-facing analytics using a hybrid database architecture.
Every system hits scaling limits in different ways, and there is no single solution that fits all. It’s about picking the right tools at the right stage of growth.
If you’re planning to scale your existing systems or build something new from the ground up, we’d love to connect.
At Tarka Labs, we focus on building high-performance solutions across Music Distribution, Royalty Processing, and Trend Analytics. Whether you are solving today’s challenges or planning for the future, we’re here to help you make it happen.