

Extracting structured data from PDFs is a common challenge across various industries. Whether you’re dealing with invoices, KYB documents, contracts, or reports, automating this process can significantly save time and reduce errors. In this blog, I’ll guide you through extracting JSON data from a PDF file using Claude Sonnet, a Generative AI model, and Amazon Bedrock. We’ll break down the steps and provide sample code to run on your local machine, making it easy for you to replicate this solution.
Problem Statement
We have a sample invoice PDF that contains two pages, including details like the invoice number, total amount, and other key information.

We aim to extract specific fields from this PDF and output them in JSON format, the JSON will have following fields:
total_amount(numeric)company_name(string)currency_name(string)invoice_no(string)invoice_date(string)
Solution Overview
While many extraction tools are available to solve this, A Generative AI (Gen AI) model offers the most straightforward programmatic solution for this task. The way Gen AI models work is, it accepts an input images and along with the user Prompt(contains the info of what the user want) and it returns the response.
Here’s a brief overview of the tools we’ll use:
- Claude Sonnet: A powerful Generative AI model that can understand and process both text and images.
- Amazon Bedrock: A managed service that provides a single API for calling foundational models from various providers, including Anthropic Claude Sonnet. (you can find the set of models managed by Amazon Bedrock here)
We’ll use the Claude Sonnet 3.5 model to extract structured data from the PDF file. To interact with it, we’ll leverage Amazon Bedrock. We’ll employ Python libraries to make it all work.
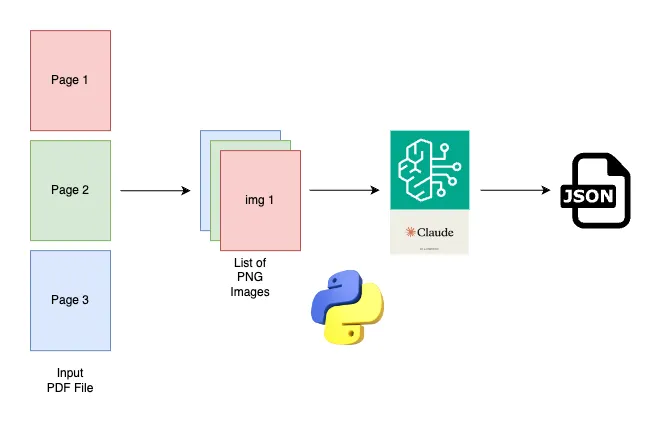
Claude request structure
The following fields are required to trigger the Claude model:
anthropic_version: The Bedrock-specific version for the Anthropic model. In our case, we’ll use bedrock-2023–05–31.max_tokens: The maximum number of output tokens to generate.messages: Each message will contain details about the model prompt, including itscontentandrole.
Thecontentfield represents the input, which can be in the form of text or images. If the input is an image, it must be sent as a base64-encoded string. Base64 encoding is a straightforward method for sharing binary data over the internet. You can simply set the encoded string in the request body’s JSON field. Therolefield can be either “user” or “assistant.” A message with a “user” role contains the user’s query. A message with an “assistant” role represents the Claude model’s response.
# Sample Claude model request body
{
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 1024,
"messages": [
{
"role": "user",
"content": [
{
"type": "image",
"source": {
"type": "base64",
"media_type": "image/jpeg",
"data": "iVBORw..."
}
},
{
"type": "text",
"text": "What's in these images?"
}
]
}
]
}To create the message request structure above, we first need to split the PDF pages into base64-encoded images.
Amazon bedrock setup
First, we’ll create a Bedrock runtime using the boto3 Python library to interact with the Claude Sonnet model.
def get_bedrock_runtime() -> any:
client = boto3.client('bedrock-runtime')
return client- get_bedrock_runtime simply creates the Bedrock runtime.
Assuming your current AWS session has access to Amazon Bedrock, if necessary, pass the credentials explicitly to the boto3.client method like this:
client = boto3.client('bedrock-runtime', aws_access_key_id='xxxxx',
aws_secret_access_key='xxxxx')Now let’s use the Bedrock runtime to invoke Bedrock models:
MODEL_ID = "anthropic.claude-3-5-sonnet-20240620-v1:0"
def run_multi_modal_prompt(req_body):
try:
bedrock_runtime = get_bedrock_runtime()
response = bedrock_runtime.invoke_model(
body=req_body, modelId=MODEL_ID)
response_body = json.loads(response.get('body').read())
return response_body
except ClientError as e:
print('unable to create bedrock runtime', e)
raiserun_multi_modal_promptwill invoke the model which we will mention in the request body.req_bodycontains the user prompt details and other metadata required to call the Claude Sonnet model.- First, it will get the Bedrock client using
get_bedrock_runtime, then it will invoke the model using the model IDanthropic.claude-3-5-sonnet-20240620-v1:0, which is the latest version of Claude Sonnet. - The
invoke_modelmethod will return a response, and we're simply extracting the response body and converting it to a JSON object. So, we're returning the result as a dictionary.
File Reader
We can use the open function to read a file in binary mode. Here's a function to get the bytes of a file:
def get_file_bytes(file_path:str) -> bytes:
with open(file_path, "rb") as file:
file_bytes = file.read()
return file_bytesSplit PDF into images
Claude model supports three formats: JPEG, PNG, and WEBP. We will use PNG because it generally has higher quality compared to the other two formats.
We will use the pdf2image library to split the PDF file’s pages into PNG images. Then, we will convert these images into base64-encoded strings.
def split_pdf_pages(pdf_bytes:bytes, max_size:tuple=(1024, 1024)) -> list[str]:
images = convert_from_bytes(pdf_file=pdf_bytes, fmt='png')
for img in images:
# resize if it exceeds the max size
if img.size[0] > max_size[0] or img.size[1] > max_size[1]:
img.thumbnail(max_size, Resampling.LANCZOS)
res = list(map(b64_encoded_str, images))
return res
def b64_encoded_str(img: Image) -> str:
byte_io = io.BytesIO()
img.save(fp=byte_io, format='PNG', quality=75, optimize=True)
# uncomment the below line, to visualize the image we are sending
# img.save(f'pdf2img_{str(time.time())}.png') <-- saves the png file
return base64.b64encode(byte_io.getvalue()).decode('utf8')- The
split_pdf_pagesfunction takes a PDF's byte content and an optional maximum size as input. It splits the PDF into PNG images usingconvert_from_bytes, resizes images exceeding the maximum size to prevent excessive data, and converts each image to a base64-encoded string usingmapandb64_encoded_str. The function returns a list of base64-encoded strings representing the images - The
b64_encoded_strfunction takes a Pillow Image object as input. It creates an in-memory byte stream, saves the image to the byte stream in PNG format with quality and optimization settings, and optionally saves the image to a file for visualization.
Building the Bedrock Request Body
We will now use the previously defined methods to construct the Claude model request body.
def build_claude_req_body(file_path:str) -> dict:
file_bytes = get_file_bytes(file_path)
base64_encoded_pngs = split_pdf_pages(file_bytes)
messages = [
{
"role": "user",
"content": [
*[
{
"type": "image",
"source": {
"type": "base64",
"media_type": "image/png",
"data": base64_encoded_png
}
} for base64_encoded_png in base64_encoded_pngs
],
{
"type": "text",
"text": USER_PROMPT
}
]
}
]
req_body = {
"anthropic_version": BEDROCK_ANTHROPIC_VERSION,
"messages": messages,
"system": SYSTEM_ROLE,
'max_tokens': 100
}
return req_body- The
build_claude_req_bodyfunction accepts the input PDF file path and returns the request body that will be used to trigger the Amazon Bedrock runtime. This function first reads the file bytes usingget_file_bytesand then converts the PDF bytes data to a list of base64-encoded strings usingsplit_pdf_pages. It then creates a list of messages, builds the request body, and finally returns it.
Let’s examine the USER_PROMPT and SYSTEM_ROLE used in the request body:
USER_PROMPT = '''
Find the following fields and put it in JSON and don't return any thing else
total_amount: numeric,
company_name: str,
currency_name: str,
invoice_no: str,
invoice_date: str
'''
SYSTEM_ROLE = 'You are an Expense Bill Analyst'SYSTEM_ROLEis primarily used to establish a domain-specific role. While it’s not mandatory, it can be helpful if you want your Model to become a specialized expert in a particular domain rather than a general assistant.- In
USER_PROMPT, we are simply specifying the field names that we need to extract, and Claude Sonnet is intelligent enough to understand each field on its own. We are also explicitly stating that only the JSON output should be returned, excluding any additional text. We have tested this with Sonnet 3.5 version, and it has consistently produced only the JSON output. If the model were to return any fillers in the completion, such as "Here is the JSON output" or "total amount is xxxxx and we found it in the second image," you could prefill the prompt with an assistant role as mentioned here.
Putting It All Together
Let’s combine everything into a single method that accepts the file path and returns only the JSON object as a result.
def extract_data(file_path):
try:
body = build_claude_req_body(file_path)
response = run_multi_modal_prompt(req_body=json.dumps(body))
print('Model response')
print(response)
d = json.loads(response['content'][0]['text'])
return d
except Exception as e:
print('something went wrong', e)
return {}- The
extract_datafunction accepts the file path, builds the Claude request body usingbuild_claude_req_body, triggers therun_multi_modal_prompt, processes the response, and returns only the message content as a JSON object.
An example of an Amazon Bedrock response looks like the following:
{
"id": "msg_bdrk_01Rq6zsWD34B1m5vyvxuQERX",
"type": "message",
"role": "assistant",
"model": "claude-3-5-sonnet-20240620",
"content": [
{
"type": "text",
"text": "<Claude model generated text...>"
}
],
"stop_reason": "end_turn",
"stop_sequence": null,
"usage": { "input_tokens": 2219, "output_tokens": 70 }
}We can find the assistant-generated text in the response['content'][0]['text'] field. To understand more about the response fields, refer here
Here’s how you can use extract_data function, just pass the input file path:
result = extract_data(invoice_pdf_file_path)
print(result)The printed result will look like this:
{
'total_amount': 5715.0,
'company_name': 'META LEGAL & FINANCE',
'currency_name': 'USD',
'invoice_no': '00000135',
'invoice_date': '12 March 2024'
}Conclusion
We’ve successfully demonstrated a method for extracting structured data from PDF files using the Claude Sonnet model and Amazon Bedrock. This approach can be adapted for various types of documents, making it a versatile tool for automation. If you’re dealing with similar challenges, give this approach a try and see how it can streamline your workflow. The complete setup can be found here
That’s a wrap, Thanks for reading!


