

Problem statement
Speech-to-Text (STT) is the process of converting audio data into text format. At a high level, our requirement is to transcribe call recordings located in an Azure storage container using Azure Batch Transcription. We then need to process this transcribed data and save it to an AWS S3 bucket.
In this article, we’ll explore how to leverage Azure Batch Transcription for transcribing audio data and utilize AWS Step Functions to create and process the final results in an automated, end-to-end fashion.
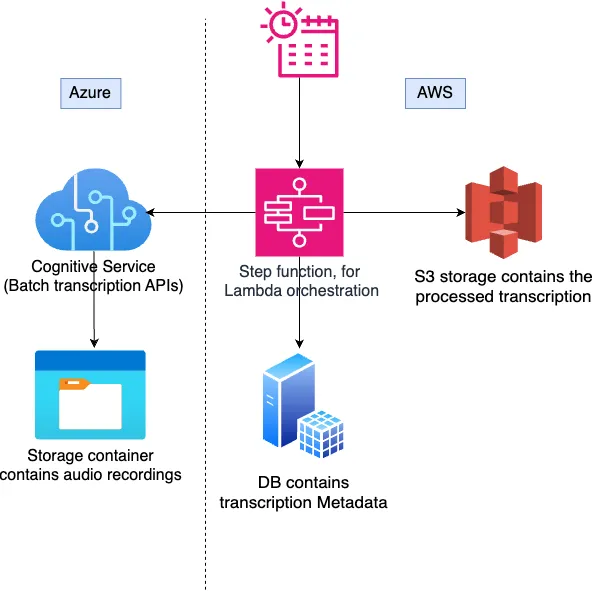
Azure batch transcription
Azure cognitive service provides a batch transcription service for transcribing large amounts of audio to text. It offers various rest APIs to manage batch transcriptions. The process works as follows:
Send audio recordings: Use the Create Transcription API to submit your set of audio recordings.
Job processing: The system starts processing the recordings in the background.
Status check: You can use the Get Transcription API to check the status of the job periodically.
Download results: Once the job is complete, use the Get Transcription Files API to retrieve a list of downloadable links for the transcribed text.
Create transcription API
Create transcription API will create transcription job with the given properties,
curl --location 'https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2-preview.1/transcriptions' \
--header 'Content-Type: application/json' \
--header 'Ocp-Apim-Subscription-Key: {subscription key}' \
--data '{
"properties": {
"punctuationMode": "DictatedAndAutomatic",
"profanityFilterMode": "Masked",
"timeToLive": "PT8H",
"diarizationEnabled": true,
"diarization": {
"speakers": {
"minCount": 1,
"maxCount": 5
}
}
},
"model": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2-preview.1/models/base/71cbd7af-3212-43ab-8695-666fb28ffef7"
},
"locale": "en-US",
"displayName": "testing transcription",
"contentUrls": [
"container_url1",
"container_url2",
"container_url3"
]
}'Some highlights in the request body:
- Model: We are using the whisper large-v2 model. You can find other available models using the Get Base Models API. Please note that the whisper model does not provide lexical text in the results.
- Diarization: We have set the diarization property to a minimum of 1 speaker and a maximum of 5 speakers.
- Time to Live: We have configured a time-to-live of 8 hours. This means that all transcription resources will be automatically deleted after 8 hours.
-
Content URLs: Content URLs must be accessible by Azure. You can use any public URL or configure the data in an Azure storage container and provide the blob URL as the content URL. If you want to add more security and protect your data with Azure’s private network, you can use Bring Your Own Storage (BYOS).
The Create Transcription API returns a created transcription resource containing a
transcription_id. You can use this ID to fetch the transcription results.
Get transcription API
Get transcription API is used to get the transcription details, it tells us the current status of the transcription Job and the other transcription properties.
curl --location \
'https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2-preview.1/transcriptions/{transcription_id}'\
--header 'Ocp-Apim-Subscription-Key: {subscription key}'Get transcription files API
Get transcription files API will give the transcription results,
curl --location \
'https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2-preview.1/transcriptions/{transcription_id}/files'\
--header 'Ocp-Apim-Subscription-Key: {subscription key}'The response will include a link field, which you can use to download the data.
It will also include a kind field. If the kind is Transcription, the link will contain the transcription result.
If the kind is TranscriptionReport, the response will provide the following information:
- The number of recordings successfully transcribed
- The number of recordings that failed transcription.
# TranscriptionReport data
{
"successfulTranscriptionsCount": 1,
"failedTranscriptionsCount": 2,
"details": [
{
"source": "content_url1",
"status": "Succeeded"
},
{
"source": "content_url2",
"status": "Failed",
"errorMessage": "Reason RecordingsUriNotFound, Details: Input file was not found at the provided URI. StatusCode: BlobNotFound. (JobId e6a0f478-a2ca-4f34-ad70-976713bc7ab0).",
"errorKind": "RecordingsUriNotFound"
},
{
"source": "content_url3",
"status": "Failed",
"errorMessage": "Reason RecordingsUriNotFound, Details: Input file was not found at the provided URI. StatusCode: BlobNotFound. (JobId e6a0f478-a2ca-4f34-ad70-976713bc7ab0).",
"errorKind": "RecordingsUriNotFound"
}
]
}AWS Step function
AWS Step Functions works like a state machine. You can define the start, next, and end states using Amazon States Language (ASL). Each state accepts an input, allows you to define tasks to be performed, and produces an output. This output becomes the input of the next state, if any.
Step Functions supports a variety of types, including task, wait, choice, parallel, and map.
You can also embed other AWS services within a particular state, such as Lambda, SQS, SNS, and Batch jobs.
Task state config for Lambda resource
Task states can handle the invocation of Lambda functions, and the return value of each Lambda function becomes the input for the subsequent state. Task state definition will look like this,
"<State name>": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"Payload.$": "$",
"FunctionName": "<LAMBDA_ARN>"
},
"InputPath": "$.transcription",
"ResultPath": "$.data"
"ResultSelector": {
"status.$": "$.Payload.status"
},
"Retry": [
{
"ErrorEquals": [
"Lambda.ServiceException",
"Lambda.AWSLambdaException",
"Lambda.SdkClientException",
"Lambda.TooManyRequestsException"
],
"IntervalSeconds": 1,
"MaxAttempts": 5,
"BackoffRate": 2
}
],
"Catch": [
{
"ErrorEquals": [
"Error1",
"Error2",
"Error3"
],
"Next": "Fail State 1",
"ResultPath": "$.error"
},
{
"ErrorEquals": [
"Error4",
"Error5"
],
"Next": "Fail State 2",
"ResultPath": "$.error"
}
],
"Next": "<Next state name>"
}We’ve added a catch and retry block. Because Lambdas are anonymous and their availability can’t be guaranteed, we’ve implemented a retry block to handle any Lambda-related exceptions.
Additionally, we’ve included a catch block to capture specific known errors and route them to appropriate next states.
If the Lambda throws errors like Error1, Error2, and Error3, the next state will be Fail State 1.
Conversely, if the Lambda throws errors like Error4 and Error5, Fail State 2 will be invoked as the next state.
Input & Output management
Each state’s input and output are in JSON format.
- Parameters allow us to define the Payload for the Lambda function and pass information about associated AWS resources. If you declare a Payload variable, the Lambda’s output will be written to that variable.
- The InputPath filter selects a specific portion of the payload. For instance, setting the $.transcription value in the InputPath allows the Lambda function to receive the transcription field’s value from the payload.
- ResultSelector is used to choose specific fields from the Lambda output. The resulting data is written to the field set by the ResultPath. For example, if you set the ResultPath value to $.output, the output of ResultSelector will be placed inside the output field, combining it with the input payload.
Now, let’s see how we automated batch transcription from creation to fetching. We used four Lambdas:
- One to create a transcription
- One to check the transcription status
- One to get the transcription files
- One to process the transcription links
All API clients and business logic within the Lambdas are written in Python. We use the requests package for making HTTP calls and boto3 for AWS operations. We have added a retry mechanism for both the requests and boto3 clients.
Now, let’s see how we assembled the Lambdas in our Step Function to enable batch transcription functionality.
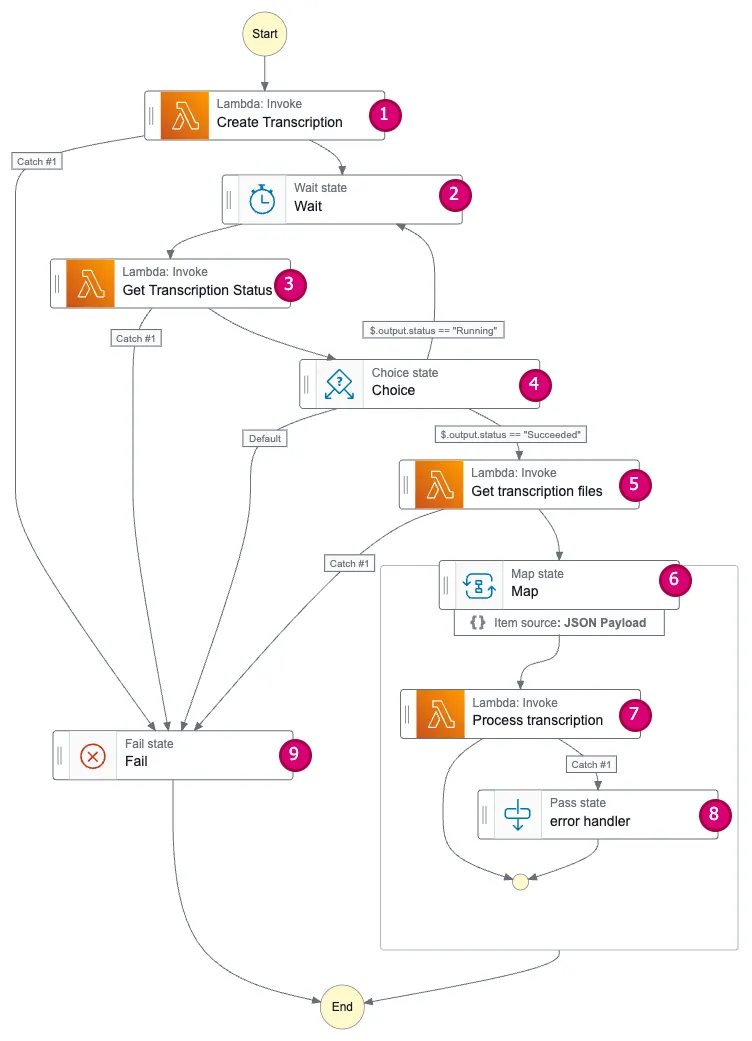
Let’s discuss the various step function states we have used here,
1. Create Transcription state
This Task state invokes the Create Transcription Lambda, which implements the logic to initiate batch transcription for a pre-defined list of audio recording URLs. The Lambda function then returns the transcription ID as its output.
2. Wait state
The Wait state is used to pause a particular state for N seconds. In our case, we need to wait for the transcription job to complete before we can fetch the results. Therefore, we invoke the Get Transcription Status state every N seconds.
"Wait": {
"Type": "Wait",
"Seconds": 300,
"Next": "Get Transcription Status"
}3. Get transcription status state
This is a Task state that invokes the Get transcription status Lambda. It contains the logic for fetching the transcription status and returns the status in the output.
4. Choice state
Choice states function similarly to switch statements, allowing you to route the flow to appropriate states based on input values. In our Choice state, the input is the transcription status. If the status is running, the flow returns to the Wait state (this combination of Choice and Wait states enables us to simulate a loop flow within the state machine). If the status is succeeded, the flow progresses to the Get Transcription Files state. For any other status value, the flow defaults to the Fail state.
"Choice": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.output.status",
"StringEquals": "Running",
"Next": "Wait"
},
{
"Variable": "$.output.status",
"StringEquals": "Succeeded",
"Next": "Get transcription files"
}
],
"Default": "Fail"
}5. Get transcription files state
This state contains the Get Transcription Files Lambda. The Get Transcription Files Lambda retrieves the transcription results and returns a list of links, each containing either the transcription report or the transcription data.
6. Map state
The Map state executes tasks concurrently. It accepts a list of items as input, and you can define task states to process each item in parallel. In our case, we’ve defined the Process Transcription state to handle the transcription results. The Map state comes in two variants: INLINE and DISTRIBUTED. You can use INLINE if the number of concurrent iterations won’t exceed 40.
"Map": {
"Type": "Map",
"ItemProcessor": {
"ProcessorConfig": {
"Mode": "INLINE"
},
"StartAt": "Process transcription",
"States": {
"Process transcription": {"Type": "Task",...},
"error handler": {"Type": "Pass", ...}
}
},
"End": true
}7. Process transcription state
This is a Task state that invokes the Process Transcription Lambda. The Process Transcription Lambda function downloads, formats, and saves the results to our system.
8. Error handler state
The Map state includes an error handler state. If an unknown runtime exception occurs during any concurrent iteration, the Map state would typically stop the entire iteration. For example, imagine you have 10 concurrent iterations and one of them fails. In such a scenario, the Map state might halt all other executions. To prevent this, we’ve defined an error handler state that acts as a Pass state. This mechanism provides a fallback in case of failures, allowing other iterations to continue processing.
"error handler": {
"Type": "Pass",
"End": true
}9. Fail state
The Fail state in the Step Function flow is used to capture failures. There are scenarios where you need to divert the flow to this state. For example, if any error occurs in the Create Transcription, Get Transcription Status, or Get Transcription Files states, we set the next step as the Fail state. An explicit Fail state allows you to set up CloudWatch alarms, collect metrics, and perform other actions in response to failures.
"Fail": {
"Type": "Fail"
}Step Functions are a powerful tool for orchestrating Lambda invocations. While Azure Batch Transcription can accept 300 requests per minute, each request is limited to around 1,000 recording files. To bring transcription results into your system quickly and efficiently, it’s recommended to split your audio files into batches of 10–15 recordings each and make multiple Create Transcription calls. This approach effectively manages Azure Batch Transcription’s request limits while ensuring a smooth, efficient workflow for your audio data.
Note: We used polling to periodically check the transcription status due to business logic constraints. While our approach is functional, Azure Cognitive Service web hooks offer an alternative solution.
Conclusion
In this post, we explored Azure Batch Transcription APIs and demonstrated how Step Functions can orchestrate Lambdas for seamless data transcription. That’s a wrap! Thanks for reading!


