Struggling with slow bulk inserts in Java? This guide benchmarks six strategies, from Hibernate to high-performance database-native methods, using datasets of up to 10 million records. Learn which approach is fastest, how to optimize inserts, and when it makes sense to ditch ORM for raw SQL speed.
Problem Statement
Imagine you’re tasked with inserting millions of records into a PostgreSQL database. You’re limited to Java and multithreading, no Kafka, no RabbitMQ. How do you get the best performance?
I recently faced this exact challenge and experimented with six different strategies:
- Spring Data JPA
saveAll() - Hibernate batch insertion with
EntityManager - Multithreaded Hibernate with connection pooling
- Native SQL batch execution
- PL/SQL stored procedure calls
COPYcommand using CSV input
This blog walks you through each approach, shares real benchmarks, and helps you pick the right one based on your workload and system limitations.
Sample Data Format
We’ll insert user permission records into the database, assuming they come from upstream systems in the following format:
[
{
"user_id": "user_1",
"entity_id": "entity_1cf156da-280d-4f07-aa16-3bdbfb1fff13"
},
{
"user_id": "user_2",
"entity_id": "entity_4d56783c-2add-49b2-ad53-080c6737e37d"
}
]Each entry represents that a user_id has permission to access a particular entity_id.
Project Setup
GitHub Repository: batch_insertion_benchmark
We’ll use PostgreSQL via a Docker container:
docker run --name my-postgres \
-e POSTGRES_USER=postgres \
-e POSTGRES_PASSWORD=postgres \
-e POSTGRES_DB=testdb \
-p 5432:5432 \
-v pgdata:/var/lib/postgresql/data \
-d postgres:15We’ll use Spring Boot with JPA (backed by Hibernate). Key dependencies:
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.15</version> <!-- Latest in 2.x -->
</parent>
...
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>42.5.4</version>
</dependency>
</dependencies>Make sure to set your PostgreSQL connection details in src/main/resources/application.properties:
# === DATABASE CONFIGURATION ===
spring.datasource.url=jdbc:postgresql://localhost:5432/testdb
spring.datasource.username=postgres
spring.datasource.password=postgres
spring.datasource.driver-class-name=org.postgresql.Driver
# === JPA / HIBERNATE SETTINGS ===
spring.jpa.database-platform=org.hibernate.dialect.PostgreSQLDialect
spring.jpa.hibernate.ddl-auto=updateAdjust the username and password as per your local setup. This project uses Java 8 and is built with Maven
Entity Definition
We’ll define a composite unique constraint on user_id and entity_id to avoid duplicates, and include an auto-generated primary key for the table:
@Entity
@Table(
name = "user_entity_permission",
uniqueConstraints = @UniqueConstraint(columnNames = {"user_id", "entity_id"})
)
public class UserEntityPermission {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "user_id", nullable = false)
private String userId;
@Column(name = "entity_id", nullable = false)
private String entityId;
...
}Strategy Interface
We define an interface to plug in multiple strategies:
public interface UserEntityPermissionBulkInsertStrategy {
void bulkInsert(List<UserEntityPermission> permissions);
String getStrategyName();
}We’ll use two methods: bulkInsert will accept the list of permissions, and its job is to insert those permissions into the DB. The other method, getStrategyName, will simply be used to get the name of the strategy.
We’ll now walk through each of the six strategies,
Strategy 1: Spring Data JPA saveAll()
For many developers, repository.saveAll() is the default approach for inserting multiple records. The implementation looks like this:
@Component("repositorySaveAllStrategy")
@Order(1)
public class RepositorySaveAllInsertStrategy implements UserEntityPermissionBulkInsertStrategy {
private final UserEntityPermissionRepository repository;
public RepositorySaveAllInsertStrategy(UserEntityPermissionRepository repository) {
this.repository = repository;
}
@Override
public void bulkInsert(List<UserEntityPermission> permissions) {
repository.saveAll(permissions);
}
...
}While you can configure the batch size in your application properties using ,
spring.jpa.properties.hibernate.jdbc.batch_size = 1000this setting will be ineffective in this specific case. Due to the use of an auto-increment ID (GenerationType.IDENTITY), Hibernate is forced to insert each row separately and wait for the generated key before proceeding. When dealing with 1 million records, this translates to executing one insert statement a million times, which significantly increases the overall processing duration.
Strategy 2: Multithreaded Hibernate with connection pooling
By using the EntityManager explicitly, we can control when to insert records and when to clear memory. Hibernate works by keeping entities in the persistence context (first-level cache) after calling persist(), but they remain in memory until a flush() is triggered. The database insert operations are flushed either explicitly or automatically during transaction commit. Until then, entities are held in memory in the persistence context.
@Component("entityManagerStrategy")
@Order(2)
public class HibernateEntityManagerStrategy implements UserEntityPermissionBulkInsertStrategy {
@PersistenceContext
private EntityManager entityManager;
@Override
@Transactional
public void bulkInsert(List<UserEntityPermission> permissions) {
int batchSize = 1000;
for (int i = 0; i < permissions.size(); i++) {
entityManager.persist(permissions.get(i));
if (i % batchSize == 0 && i > 0) {
entityManager.flush();
entityManager.clear();
}
}
entityManager.flush();
entityManager.clear();
}
...
}You can fine-tune the batch size, but it still works best for a few thousand records.
Strategy 3: Hibernate Batch Insertion With Concurrency
To scale better, we can split the dataset across multiple threads. Each thread gets its own EntityManager and handles batching independently in a separate transaction.
@Component("entityManagerWithConcurrencyStrategy")
@Order(3)
public class HibernateEntityManagerWithConcurrency implements UserEntityPermissionBulkInsertStrategy {
private static final int THREADS = 5;
private static final int BATCH_SIZE = 1000;
@PersistenceUnit
private EntityManagerFactory entityManagerFactory;
private final PlatformTransactionManager transactionManager;
public HibernateEntityManagerWithConcurrency(PlatformTransactionManager transactionManager) {
this.transactionManager = transactionManager;
}
@Override
public void bulkInsert(List<UserEntityPermission> permissions) {
int chunkSize = (int) Math.ceil((double) permissions.size() / THREADS);
ExecutorService executor = Executors.newFixedThreadPool(THREADS);
for (int i = 0; i < THREADS; i++) {
int start = i \* chunkSize;
int end = Math.min(start + chunkSize, permissions.size());
List<UserEntityPermission> subList = permissions.subList(start, end);
executor.submit(() -> {
TransactionTemplate template = new TransactionTemplate(transactionManager);
template.execute(status -> {
EntityManager em = entityManagerFactory.createEntityManager();
try {
em.getTransaction().begin();
for (int j = 0; j < subList.size(); j++) {
em.persist(subList.get(j));
if (j > 0 && j % BATCH_SIZE == 0) {
em.flush();
em.clear();
}
}
em.flush();
em.clear();
em.getTransaction().commit();
} catch (Exception e) {
System.err.println("something went wrong " + e);
e.printStackTrace();
if (em.getTransaction().isActive()) {
em.getTransaction().rollback();
}
} finally {
em.close();
}
return null;
});
});
}
executor.shutdown();
...
}This method performed better than the first two strategies, but you need to set the connection pool settings properly; otherwise, you will face connection errors because many threads are trying to access the same DB connection. Make sure your connection pool supports parallel inserts by configuring these Hikari settings:
spring.datasource.hikari.maximum-pool-size=30
spring.datasource.hikari.minimum-idle=5
spring.datasource.hikari.idle-timeout=10000
spring.datasource.hikari.connection-timeout=30000
spring.datasource.hikari.max-lifetime=1800000Strategy 4: Native SQL batch execution
An efficient alternative is to use native SQL with batch inserts, where all records are inserted in a single operation using JdbcTemplate. It’s very easy to achieve this using the JdbcTemplate's batchUpdate method.
@Component("nativeSqlStrategy")
@Order(4)
public class NativeSqlInsertStrategy implements UserEntityPermissionBulkInsertStrategy {
private final JdbcTemplate jdbcTemplate;
public NativeSqlInsertStrategy(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
@Override
public void bulkInsert(List<UserEntityPermission> permissions) {
String sql = "INSERT INTO user_entity_permission (user_id, entity_id) VALUES (?, ?)";
jdbcTemplate.batchUpdate(sql, permissions, permissions.size(), (ps, permission) -> {
ps.setString(1, permission.getUserId());
ps.setString(2, permission.getEntityId());
});
}
...
}The batchUpdate() method allows you to specify a batch size for the operations. In this implementation, for simplicity, we are setting the batch size equal to the total number of permissions (permissions.size()). However, when testing with different large batch sizes (e.g., 1000, 10000, or 1000000), I did not observe a significant improvement in overall performance. The optimal batch size can often depend on your input data size, specific database and runtime environment, and it's recommended to tune it accordingly.
Strategy 5: PL/SQL stored procedure calls
Similar to native SQL, we can also utilize SQL procedures. To achieve this, we need to create a procedure in the DB:
CREATE OR REPLACE PROCEDURE insert_user_entity_permission(user_id TEXT, entity_id TEXT)In the implementation, we can use the same JdbcTemplate's batchUpdate method:
@Component("plSqlStrategy")
@Order(5)
public class PlSqlInsertStrategy implements UserEntityPermissionBulkInsertStrategy {
private final JdbcTemplate jdbcTemplate;
public PlSqlInsertStrategy(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
@Override
public void bulkInsert(List<UserEntityPermission> permissions) {
String sql = "CALL insert_user_entity_permission(?, ?)";
jdbcTemplate.batchUpdate(sql, permissions, permissions.size(), (ps, permission) -> {
ps.setString(1, permission.getUserId());
ps.setString(2, permission.getEntityId());
});
}
...
}Strategy 6: COPY command using CSV input
In this method, We’ll create a CSV file for the permissions and use the COPY command to upload all the data. Once the data is uploaded, We’ll clean up the CSV
@Component("csv-upload")
@Order(6)
public class CsvUploadInsertStrategy implements UserEntityPermissionBulkInsertStrategy {
private final DataSource dataSource;
public CsvUploadInsertStrategy(DataSource dataSource) {
this.dataSource = dataSource;
}
@Override
public void bulkInsert(List<UserEntityPermission> permissions) {
File tempFile = null;
try {
// Step 1: Create temp CSV file
tempFile = File.createTempFile("permissions-", ".csv");
try (BufferedWriter writer = new BufferedWriter(new FileWriter(tempFile))) {
for (UserEntityPermission permission : permissions) {
writer.write(permission.getUserId() + "," + permission.getEntityId());
writer.newLine();
}
}
// Step 2: Perform COPY operation
try (Connection conn = dataSource.getConnection();
FileReader reader = new FileReader(tempFile)) {
CopyManager copyManager = new CopyManager((BaseConnection) conn.unwrap(BaseConnection.class));
copyManager.copyIn("COPY user_entity_permission (user_id, entity_id) FROM STDIN WITH (FORMAT csv)", reader);
}
} catch (Exception e) {
throw new RuntimeException("Failed to perform CSV upload", e);
} finally {
// Step 3: Cleanup the CSV file
}
}
...
}Bulk insertions using CSV are supported by most databases in some form, and with PostgreSQL, the CopyManager makes this process exceptionally efficient.
Execution
To generate 1 million permissions, Here’s a utility method to quickly generate test data:
public static List<UserEntityPermission> generatePermissions(int count) {
List<UserEntityPermission> permissions = Collections.synchronizedList(new ArrayList<>(count));
IntStream.range(0, count).parallel().forEach(i -> {
String userId = "user-" + (i % count);
String entityId = "entity-" + UUID.randomUUID();
permissions.add(new UserEntityPermission(userId, entityId));
});
...
return permissions;
}For a given count, it will simply generate the list of permissions.
To run all the strategies, we can simply get all the beans implementing the interface because we have already defined all the strategy implementations as @Component classes and also defined the @Order for each strategy.
@Component
public class BulkInsertBenchmarkRunner {
private final List<UserEntityPermissionBulkInsertStrategy> strategies;
private final JdbcTemplate jdbcTemplate;
public BulkInsertBenchmarkRunner(
List<UserEntityPermissionBulkInsertStrategy> strategies,
JdbcTemplate jdbcTemplate) {
this.strategies = strategies;
this.jdbcTemplate = jdbcTemplate;
}
public void runBenchmark(int numberOfRecords) {
for (UserEntityPermissionBulkInsertStrategy strategy : strategies) {
List<UserEntityPermission> permissions = PermissionDataGenerator.generatePermissions(numberOfRecords);
System.out.println("Running strategy: " + strategy.getStrategyName());
clearTable();
long startTime = System.currentTimeMillis();
strategy.bulkInsert(permissions);
long endTime = System.currentTimeMillis();
long duration = endTime - startTime;
long count = countRecords();
System.out.println("Inserted: " + count + " records using " +
strategy.getStrategyName() + " in " + duration + " ms");
System.out.println("--------------------------------------------------");
}
}
private void clearTable() {
jdbcTemplate.execute("TRUNCATE TABLE user_entity_permission");
}
private long countRecords() {
return jdbcTemplate.queryForObject("SELECT COUNT(\*) FROM user_entity_permission", Long.class);
}
}In the runBenchmark method, we first clear all records from the permission table before executing each strategy. After each run, we print the number of inserted rows and the time taken, which help evaluate each strategy's performance.
So, in the main method of the application, we can simply call the runner like this to execute all the strategies:
@SpringBootApplication
public class Main {
public static void main(String\[\] args) {
ApplicationContext context = SpringApplication.run(Main.class, args);
BulkInsertBenchmarkRunner runner = context.getBean(BulkInsertBenchmarkRunner.class);
runner.runBenchmark(1_000_000);
}
}This will trigger the benchmark for 1 million records.
Benchmark Results
To understand the performance characteristics of each bulk insertion strategy across different scales, we conducted benchmarks using varying numbers of records. The tests were performed in a controlled environment. (I ran the benchmarks on a Postgres Docker container using a 12-core MacBook with an M2 chip. I didn’t apply any special JVM tuning; the Spring Boot application was run with its default settings, using Java version 8)
The primary metric measured was the total time taken to insert all records using each strategy.
Let’s examine the performance trends starting with smaller data volumes.
Performance Across Varying Data Sizes (1000 to 100000 Records)
This graph illustrates how the different strategies perform as the data size increases from a few hundred up to one hundred thousand records.
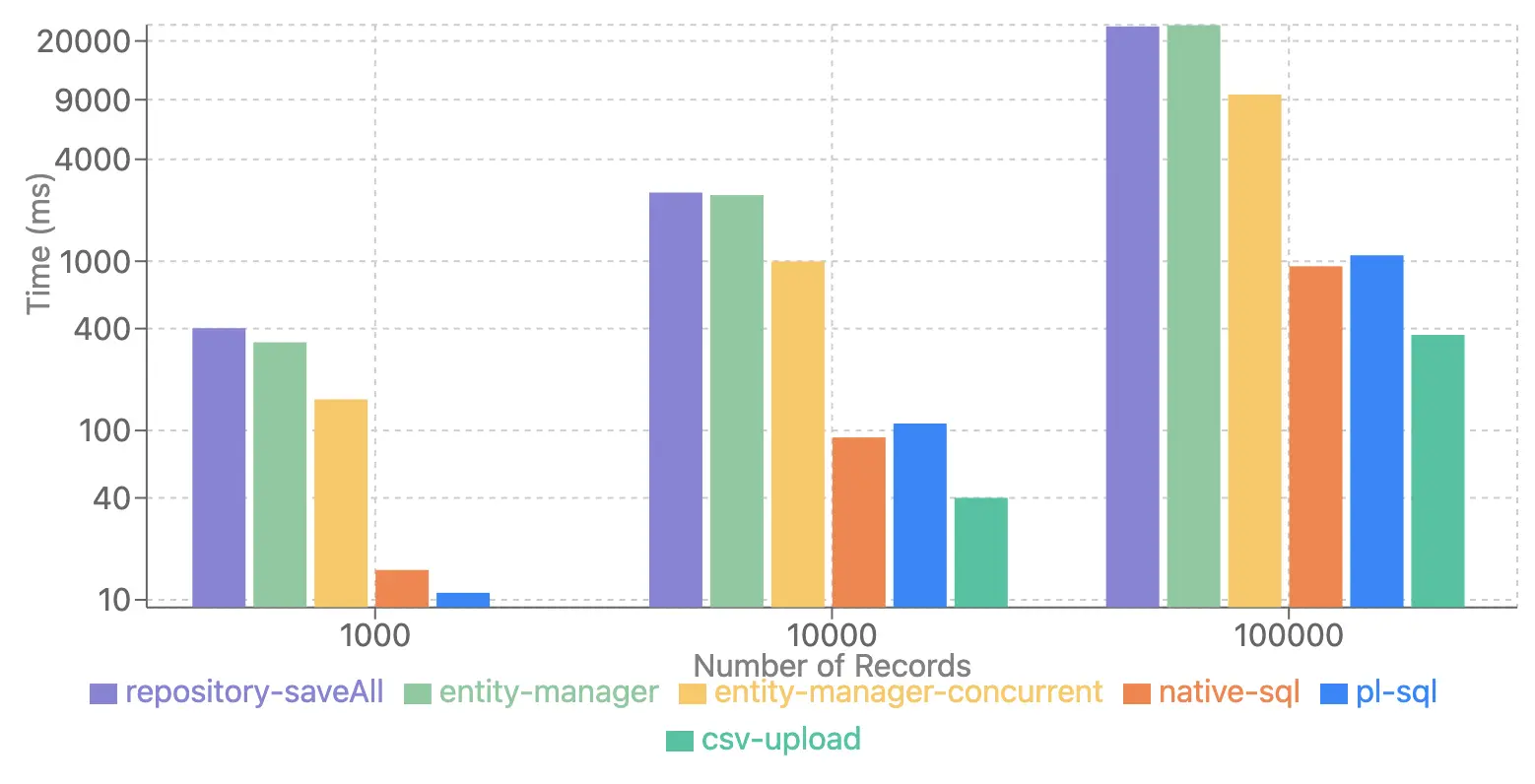
As you can see, for smaller data sizes (e.g., 1000 or 10000 records), the performance difference between the methods is less pronounced. Standard Hibernate approaches (repository-saveAll, entity-manager, and even entity-manager-concurrent) show relatively acceptable performance within the "few thousand" range. This suggests that if you typically insert only a few thousand records at a time, the convenience of using standard JPA or Hibernate batching might be sufficient.
However, the graph clearly shows that as the data size grows towards 10,000 and especially 100,000 records, the performance curves diverge significantly. The time taken by the standard Hibernate methods begins to increase much more steeply compared to the native database approaches.
Performance for 1 Million (1M) Records
Scaling up significantly, let’s look at the performance when inserting a substantial volume: 1 million records.
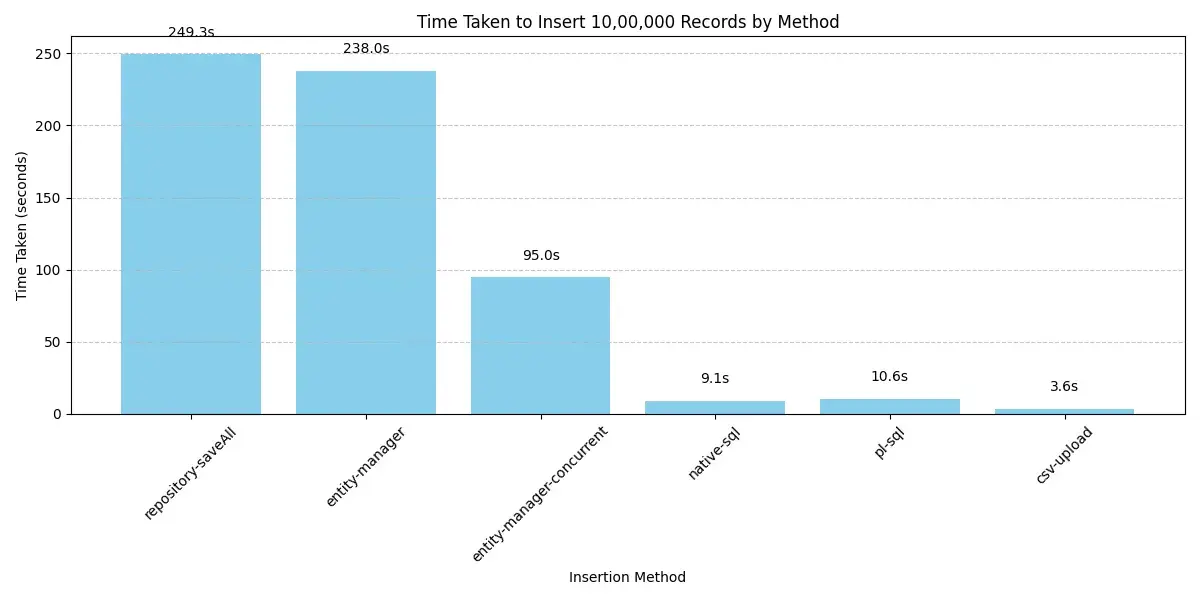
At the 1 million record mark, the limitations of standard Hibernate batching become much more apparent. The repository-saveAll and single-threaded entity-manager strategies take a considerably longer time. While the concurrent Hibernate approach (entity-manager-concurrent) offers a notable improvement over its single-threaded counterparts, it is still orders of magnitude slower than methods leveraging native database capabilities.
The Native SQL and PL/SQL strategies demonstrate their efficiency for large datasets here, completing the insertions in a fraction of the time taken by the Hibernate entity-based methods.
Performance for 10 Million (10M) Records
Pushing the boundaries further, we benchmarked the strategies with a massive 10 million records.
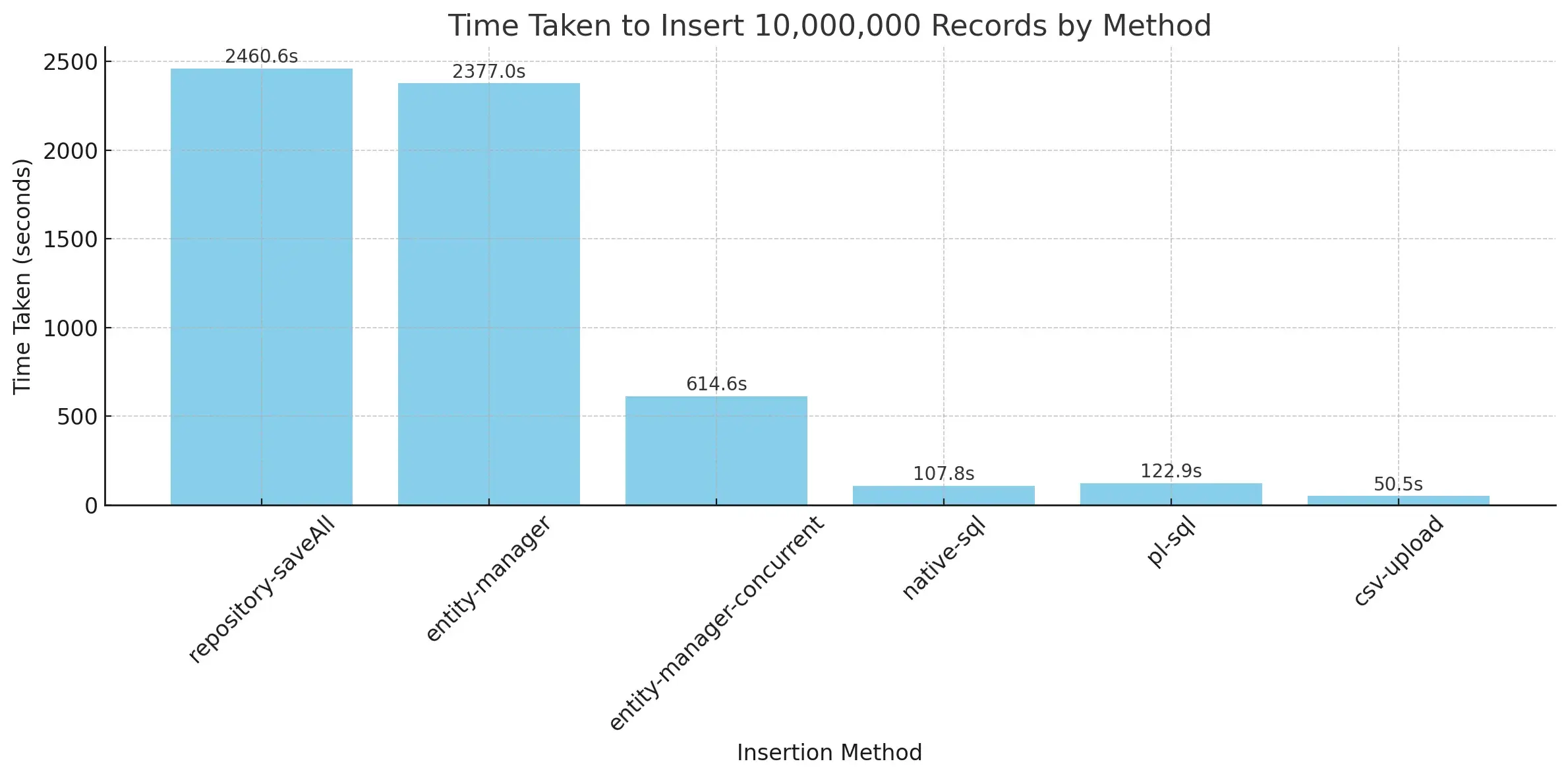
This scale truly highlights the importance of choosing an optimized strategy for very large bulk operations. The performance gap between the methods becomes even wider. While the exact numbers will vary based on hardware and database configuration, the relative performance ranking remains consistent.
The CSV COPY method stands out as the clear winner for inserting 10 million records, completing the operation far faster than any other strategy. This performance is due to it bypassing much of the overhead associated with JDBC or ORM frameworks and using the database’s highly optimized bulk loading API.
Native SQL and PL/SQL remain strong contenders at this scale and are highly recommended alternatives when the CSV method is not applicable or preferred. Standard Hibernate entity based insertions become impractical for this volume of data, taking an excessively long time.
Should We Ditch Hibernate for Bulk Insertions?
Hibernate is a great default, but when you’re dealing with serious data volumes, it’s time to look elsewhere. For performance critical batch inserts, native SQL and bulk loaders are your best bet. For truly large-scale bulk insertions (hundreds of thousands to millions of records or more), relying solely on standard Hibernate entity persistence (saveAll, persist with flushing) is not advisable due to significant performance bottlenecks.
However, this doesn’t mean you should abandon Hibernate entirely. For typical application operations involving inserting a few dozen or even a few thousand records within a standard transaction, the convenience and features of Hibernate are invaluable and the performance is usually sufficient.
The key takeaway is to select the strategy appropriate for the data volume:
- Use standard Hibernate/JPA for routine transactions and smaller batch inserts.
- Employ Native SQL or PL/SQL for significant bulk insertion tasks when you need good performance and database specific features are acceptable.
- Choose Database Native Bulk Loaders (like CSV COPY) when dealing with massive datasets and the target database supports an efficient direct loading mechanism, this is often the fastest possible method.
Understanding these performance differences allows you to make informed decisions and optimize your data insertion processes for various use cases.
Conclusion
This exploration compared various Java based strategies for high-volume bulk insertions. Our benchmarks clearly showed the CSV COPY method is the fastest for millions of records, leveraging native database bulk loading, though its availability varies by database.
When CSV isn’t feasible, Native SQL or PL/SQL via JdbcTemplate are the next most performant alternatives, proving significantly faster than standard JPA persistence for large volumes. Standard JPA methods like Repository.saveAll() are convenient for smaller batches but struggle significantly with millions of entries due to ORM overhead.
In summary, for large scale data insertion in Java:
- Prioritize Database Native Bulk Loaders (like COPY) if supported.
- Consider Native SQL or PL/SQL as highly effective alternatives.
- Use Standard JPA only for smaller batch inserts.
Choosing the right strategy depends on your data volume, performance needs, and database capabilities.
The full implementation details can be found in this repository.
Thanks for reading!