

At work one day, in a casual conversation with my teammates, the topic of Machine Learning came up. I was instantly hooked, and keenly listened to everyone talking about it.
Someone brought up the TV series “Person of Interest” — a sci-fi crime drama, which is actually based on AI. This intrigued me, and made me want to explore more.
Here is the story-line of the TV series — a computer programmer develops an application for the government that is capable of collating all sources of information to predict and identify people planning terrorist acts. Based on the predicted information, he tries to stop the crime.
How? — The entire city’s surveillance data feed would be given to the system as input. The machine would collate the relevant information by analysing the video feed, and learn the pattern that occurred in every crime activity.
Cut to a few days later, I came across an interesting project called Facenet. This project deals with Face recognition – a computer vision task of identifying and verifying a person based on a photograph of their face.
After going through the details of this project, I could relate it with the Person Of Interest TV series. I attempted to build the same thing, but by adding my own person of interest image set into the project.
The process of adding a small dataset with a pre-trained model and performing retraining is called Transfer Learning. It is much faster and extremely cost-effective because all the learnings are already done. Adding a new dataset on top of it is just a small effort of learning which will be faster and cost-effective.
In this post, I will share my experience building the project, and creating the ML model.
Before we dive into building the model, let us understand the steps involved in the building process.
To build a machine learning model, we need data and it has to undergo the following steps:
- First, the raw data needs to be curated, cleaned and organised as a dataset. In our case, it’s the set of images of each person. Generally this will be done with the help of data scientists and domain experts.
- Second, the dataset needs to be split into two. Training dataset (80%) and Test dataset (20%)
- Third, we write our own algorithm or choose an existing machine learning algorithm which is the best fit for our usecase.
- Lastly, we need to do the training by adjusting the input values till we get the expected accuracy level.
Now, it’s time to dive deep, into the hands-on 🙃
I forked the Facenet project into my Github account to do my experiments. Also, I containerised it using Docker for the faster start up and easier management. These two steps are of course optional, but I found that it made things very convenient for me.
Once this is done, here is how you too can go about building your version of this application:
Setting up the Work Environment
Ensure that Git and Docker installed on your machine.
Open the terminal and clone the project into you workspace
$ git clone https://github.com/rajivmanivannan/facenet
$ cd facenetUse the below docker compose command to build the docker image.
$ docker-compose build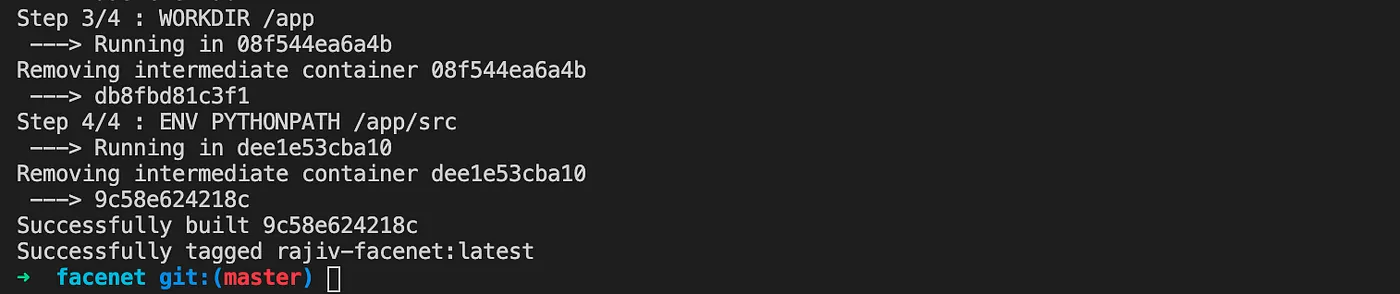
To run the dockerized application execute the below command
$ docker-compose run --rm cli bash
Run the below commands to create required directory for our work.
$ mkdir models mkdir -p datasets/lfw/raw mkdir -p
datasets/my_dataset/{train,test}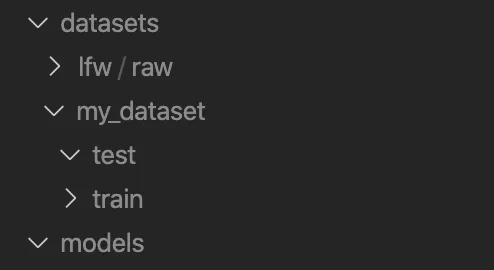
Step1 : Collecting data and creating dataset
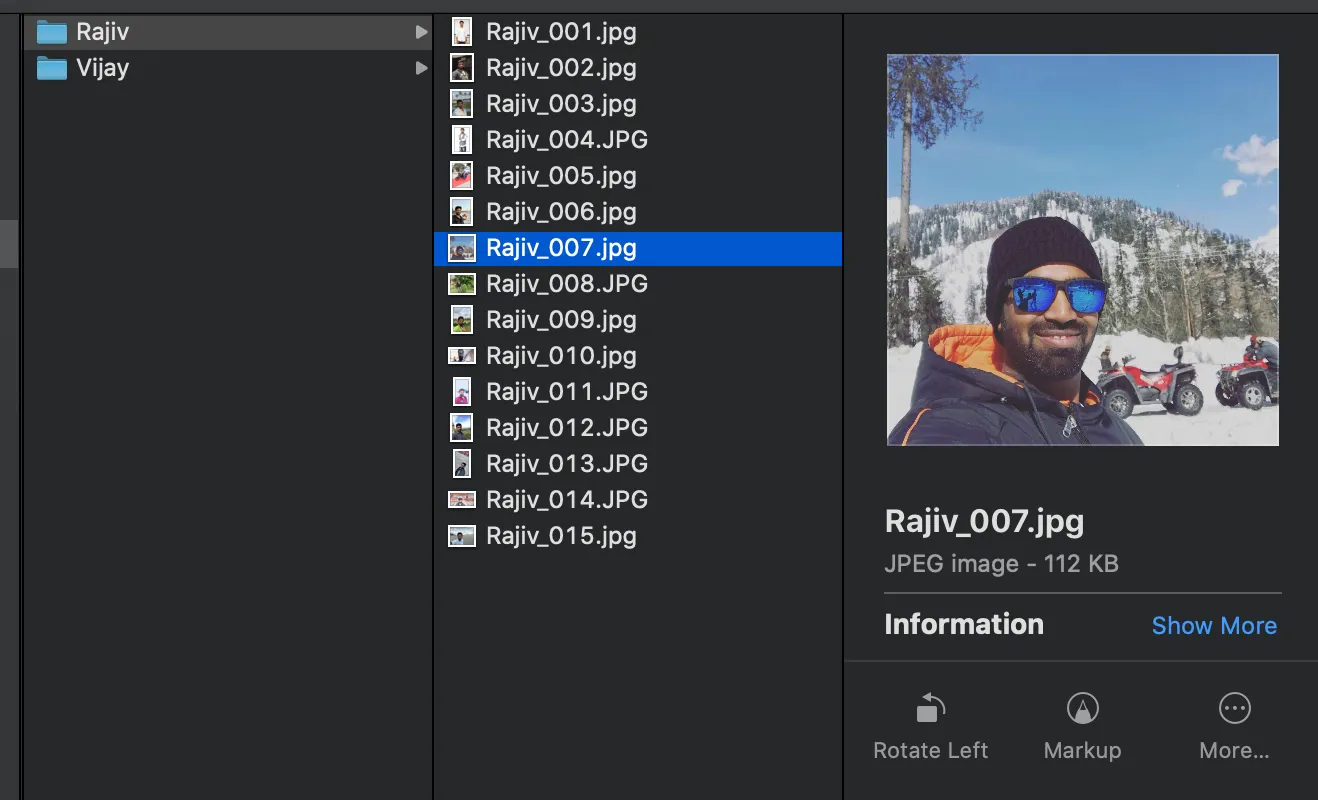
I collected images of myself and one celebrity from internet. I then organized it in two separate folders. There were around 15 image set in each folder. Then, I moved the folders into the following path /app/datasets/lfw/raw.
In this project they have used the Multi-task Cascaded Convolutional Neural Networks (MTCNN) to detect the face from the image and crop it into 160x160 images. Aligned and cropped images (the dataset) will be stored in /datasets/lfw/lfw_mtcnnpy_160. To create the dataset run the following command.
for N in {1..4}; do python src/align/align_dataset_mtcnn.py
/app/datasets/lfw/raw /app/datasets/lfw/lfw_mtcnnpy_160 --image_size
160 --margin 32 --random_order; done (Now it’s called dataset)](/blog/building-a-facial-recognition-machine-learning-model/6.webp)
Step 2: Training the ML model
We need to split the dataset — 80% to Train and 20% for Test. I took 3 images as test set form 15 images and kept aside. Then placed the dataset into the train and test folder in the following path /datasets/my_dataset/train.
And then, download the pre-trained model 20180402–114759, extract it into the models folder in the project. This model has been trained on the VGGFace2 dataset consisting of ~3.3M faces and ~9000 identities (classes).
Run the below command to train and build your own model with your dataset.
python src/classifier.py TRAIN ./datasets/my_dataset/train/
./models/20180402-114759.pb ./models/my_classifier.pb --batch_size
1000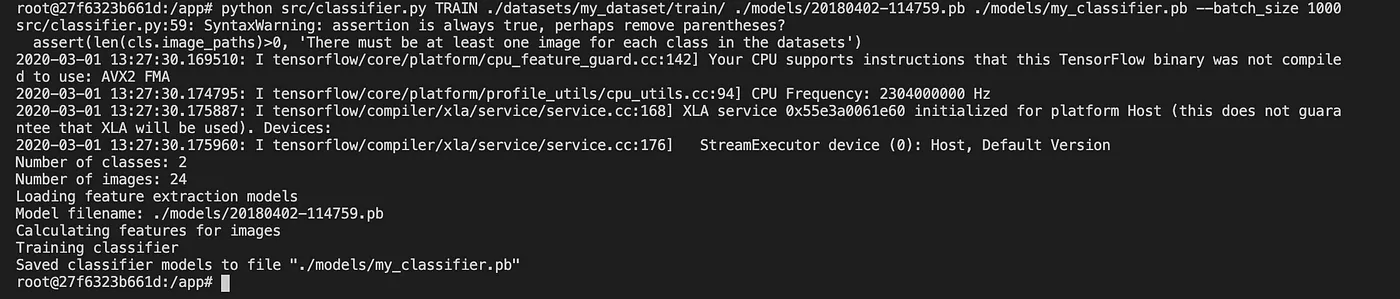
After the completion of the training it will create a new model with our dataset named my_classifer.pb. You can find in the path /models.
Step 3: Test the ML model with test dataset
Now, it’s time to test our model with test dataset. Place the test dataset in the following path /datasets/my_dataset/test. Run the below command to classify the test data against our model. It will provide the face match accuracy percentage of each image.
python src/classifier.py CLASSIFY ./datasets/my_dataset/test/
./models/20180402-114759.pb ./models/my_classifier.pb --batch_size
1000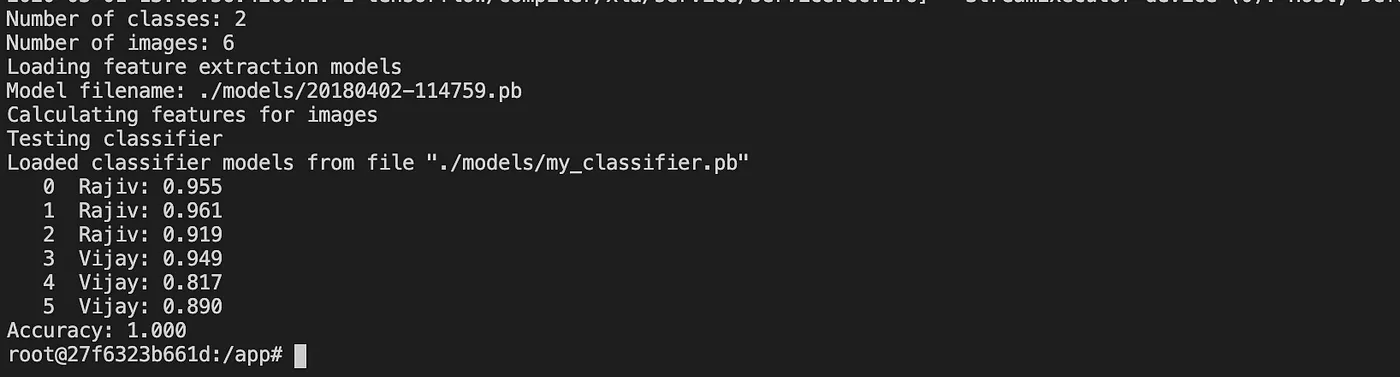
Conclusion
I believe this provides the core piece to build a full-fledged facial recognition based application. I am working on building an App to recognise my teammates and greet them by name.Will keep you posted on how it goes!


