Background
Our client is a specialized provider of medical billing, coding, and business analytics services for healthcare providers throughout the United States. Their Quality Management System (QMS) encompasses a substantial volume of recorded call audios that necessitate auditing for diverse purposes.
The manual process of reviewing these recordings is both inefficient and time-consuming, underscoring the imperative for substantial automation.
Objectives
Build and integrate an audio transcription service with Privacy, Security, Speed & Diarization
In collaboration with our customers, we began defining the project objectives, ensuring clear end goals and success criteria while considering their domain regulations, budget constraints, and business plans
Privacy and Security of Audio Data
- Ensuring the privacy and security of audio data is critical given the client’s operation in the healthcare sector.
- Preventing data from leaving their private network was also critical.
Integration of Audio Transcription with Existing QMS
- The auditing process is conducted through their in-house Quality Management System. Ensuring that the audio is transcribed and integrated with their QMS was essential.
- Transcripts were initially saved and periodically deleted to optimize storage usage and system performance.
Speaker diarization
- Incorporating diarization (identifying who spoke at specific times) into the final transcription results was important for quality checks as differentiating between speakers' voices improves the efficiency of auditing process.
Rapid Audio Transcription Results
- The end user required transcription results as quickly as possible.
- The system filters and transcribes audio data hourly, promptly saving the results
Challenges
Thousands of hours of audio content, Fault tolerance & Multi cloud infrastructure
Volume of audio content
- Since we were dealing with thousands of hours of audio recordings, building a system that can scale quickly and process audio cost effectively was critical
Fault tolerance and Recovery
- When a transcribing fails for any reason, ability to automatically identify, retry and recover from the failures was very important for smooth functioning of the transcription service
Multi cloud strategy infrastructure
- The client was using multi cloud strategy (Azure and AWS) and this complicated the whole design as the audio files and the quality management system were with different cloud providers
- Maintaining robust security measures throughout the transcription process was also crucial.
Approach
Explore, Evaluate & Verify
Large Language Model
Considering the constraints and requirements gathered from our clients, we are inclined towards an LLM-powered solution for audio transcription due to the advanced capabilities and rapid development of large language models in this domain. We have begun exploring various options that can deliver the accuracy and speed necessary to meet the demands of this project
Some of the top contenders we explored
- Wav2Vec 2.0 by Meta
- Whisper by OpenAI
- DeepSpeech by Mozilla
- Kaldi by Johns Hopkins University
System Architecture
We also started exploring different architectures that can seamlessly scale to sudden demand outbursts and keeping the cost to minimum
Seamless integration to existing systems
Since the audio transcription service needs to read from existing storage system and the results should be available in the current quality management systems, We started analysing their existing system architecture and built POC validations to identify the potential problems
Solution
OpenAI Whisper & Azure Batch Transcription Service
Among all the Audio Speech Recognition (ASR) models we evaluated, we found that OpenAI's Whisper model provides exceptional performance in audio transcription with speech diarization.
Deploying the Whisper model required a dedicated GPU/CPU instance, which incurs significant costs. Considering the client's preference for a pay-as-you-go model, we chose to use Azure Batch Transcription, which supports the Whisper model.
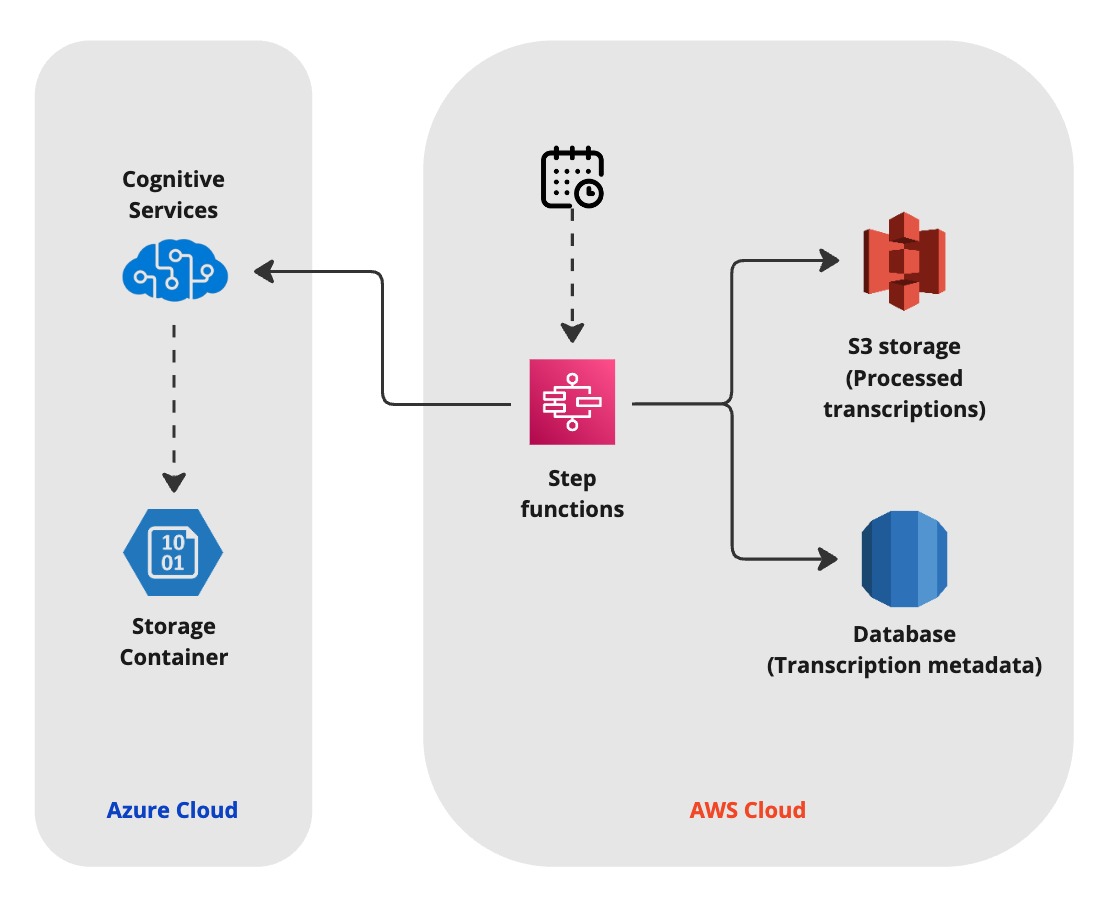
Azure Batch Transcription
We utilized Azure Batch Transcription for its robust features, including:
- Customization Options: Tailoring the process to our needs with features like diarization and selecting the Whisper model for US English.
- Bring Your Own Storage (BYOS): Keeping audio data in our existing storage infrastructure (AWS S3) while using Azure for transcription, enhancing data security.
Serverless Architecture
We built an efficient workflow using serverless technologies:
- Data Transfer: Recordings are filtered and copied from an S3 bucket to an Azure storage container for transcription every hour.
- Batch Processing: A batch transcription job is triggered using the list of recording URLs copied to the Azure storage container.
- Result Storage: Results are stored back in an S3 bucket, and metadata is saved in the QMS Application DB for future reference.
- Orchestration: All logic is written in Python and deployed on AWS Lambda. The entire workflow is orchestrated by AWS Step Functions.
Conclusion
A scalable and fault-tolerant audio transcription service that reduced auditing effort by over 50%
The system we built and deployed is transcribing numerous recordings concurrently and dramatically reducing the audit time compared to pervious manual methods.
This efficiency allowed our clients to complete audits and extract valuable insights from the audio data much faster.
With the advanced transcription system in place, we've reduced auditing time by an impressive 50%, significantly enhancing the efficiency of revenue life cycle management. The integration of this technology not only streamlines operations but also frees up valuable resources, enabling our clients to focus on strategic initiatives and drive further growth.
_tech
used
