Overview
How do you identify the right GenAI use case for your business?
In the era of rapidly evolving technologies, numerous companies, inspired by the hype surrounding GenAI, aspire to integrate it into their operations. However, many find themselves at a crossroads, unsure of how to take the crucial first step.
This case study sheds light on how Tarka Labs assisted GAEA Global, a leader in supply chain solutions, in identifying the most suitable GenAI solution for their domain specific needs.
Challenge
Extract structured data from maintenance logs and audit reports
Maintenance logs and audit reports come in different formats and are paper based. These reports are filled by hand and are archived for future reference. There are lots of business opportunities like improving operational efficiency if this treasure trove of data is digitized. Given the sheer number of different templates, building a system in a traditional sense is very time consuming and costly.

Objective
Build a solution that can work well with different templates and layouts
Our objective was to solve this problem using latest techniques powered by LLMs / ML models in achieving the following
- Extract the data across different reports and store it in a form that can be consumed and processed downstream
- Identify the structure (fields, tables) of the report and create a schema that can be used for creating digital forms for collecting data digitally
Approach
There are lots of ML powered document data extraction tools available and some are powered by LLM based AI models. We started scouting the landscape for best possible options out there and started experimenting with the top contenders in a short span of two weeks to decide on each offering capabilities.
Google Document AI
Google Document AI offers document processors that are pretrained ML models which can extract data for a specific set of documents like license card, invoice, etc. For our use case, we have to fine tune a model with a few hundreds of documents for it to extract the contextual data. This, when done, will definitely work, what we wanted was a zero shot training model so that it can work for the different types of documents that GAEA’s customers will have.
Here is the summary of our observations experimenting with different document processors
Document OCR
This processor is a plain OCR implementation that will extract the text from the given image / pdf document without any structure. All the text will be pretty much put together as blobs without any logical separation. Tabular data will not make any sense as it does not identify the columnar groupings. This was definitely not going to work for our use case
Form Parser
This processor is specialized to extract key value pairs from the given document. Which is what we would need for our use case. When we tried with different format documents, we noticed that it is able to extract around 80% of the keys and values correctly. It was also capable of understanding handwritten text and most of the time was able to infer it correctly
Custom Extractor
Google Document AI also offers Generative AI powered extractors that can identify the structure of the data better. We can also configure the keys to be extracted from the given documents. Even though there is a manual step of defining the keys (to improve the success rate of extraction), we were able to observe that this yielded better results in extracting all the needed fields values from the passed documents
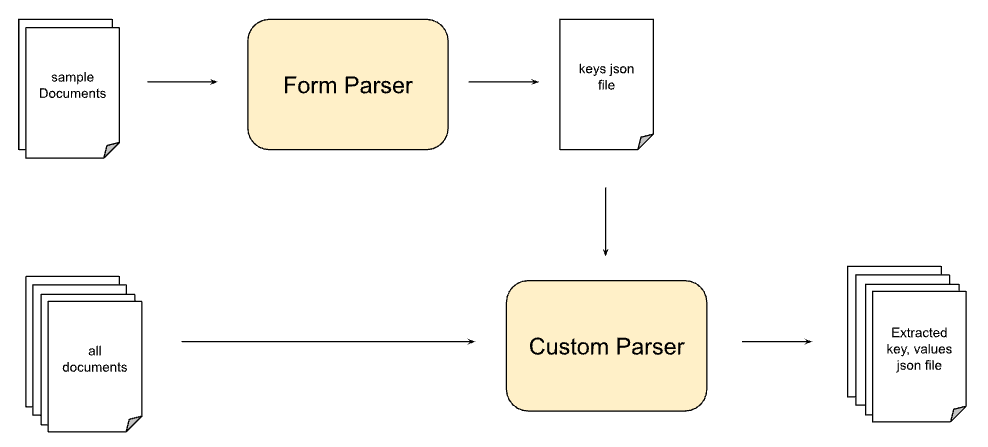
Our hybrid approach
We found that the form parser was able to extract most of the keys from the given document but the custom extractor which was powered by generative AI was able to extract the values better given the keys are already configured. So, we tried a hybrid approach where we glued together both the processors (as they have APIs) and passed our documents through this.
Much to our delight, this approach worked better than using these processors in isolation. But read through the end of this article to find out how this fared in comparison to ChatGPT4.
ChatGPT4
No Generative AI discussion is complete without comparing it with ChatGPT4 (gold standard as of Jan 2024) and we also were curious to find out how it can perform given that ChatGPT4 is multimodal (it can understand images). So, we created a small script to call its API passing each page of our document as an image to see how much it can infer.
Much to our surprise, We were able to see ChatGPT4 performing much better in extracting almost all the keys and values without any predefined keys extraction and configuration as we did in our hybrid approach.
But, The biggest downside of this approach is that we cannot tweak the output in any way. Meaning, we just have to be happy with what it gives as we cannot nudge it by specifying how to extract some parts of complex table structure or multi column structure.
Conclusion
Based on this activity we did over a period of 2 weeks, We have consolidated our learnings and challenges we foresee in this space in this section. Given the Generative AI space is fast evolving and the understanding of the LLMs is astronomically increasing as time passes, It should be noted that these findings might have a short life span (welcome the AI driven world where the cycle time for innovation is drastically reducing).
While zero shot training approaches (Form Parser / ChatGPT) get us faster to production, We don’t have much control to tweak the results to improve the accuracy. If this data is going to be part of a critical business flow, Then this approach will not work well.
Alternatively, If we can spend time to customize or finetune what we wanted to extract (Custom extractor / Hybrid approach), Even though we spend initial effort to define keys that need to be extracted for the given bucket of documents, its accuracy of data extraction will be higher and predictable.
_tech
used
